Data Pre-processing
The first step in analyzing data in R is to set your working environment and then load your data and required packages. I have already done that in the background, so I encourage you to download the code for this page if you would like to see that step. I will only show one example of code for each pre-processing step to save precious internet space.
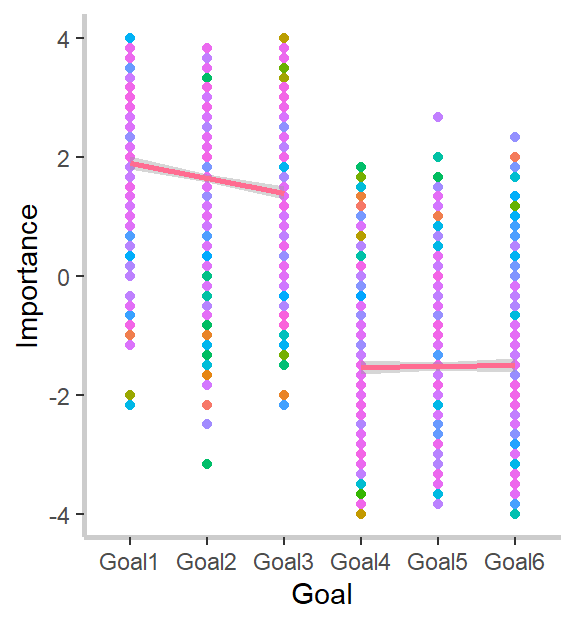
After you’ve set up your enviornment you can start pre-processing your data to get it into the necessary format for analyses. Below, I create a participant identification number (PIN) and set it as a factor. Then I rename the variables that identify exactly how important, on a 1 to 10 scale, participants viewed their three most and three least important goals.
# Creating a PIN
data1$PIN<-seq(from=1, to=length(data1$Progress))
# Setting the variable as a factor for analyses
data1$PIN<-as.factor(data1$PIN)
## Creating variables for the continuous measure of goal importance
# Most Important Goals
data1$g1Imp<-(as.numeric(data1$Q5.2)-1)
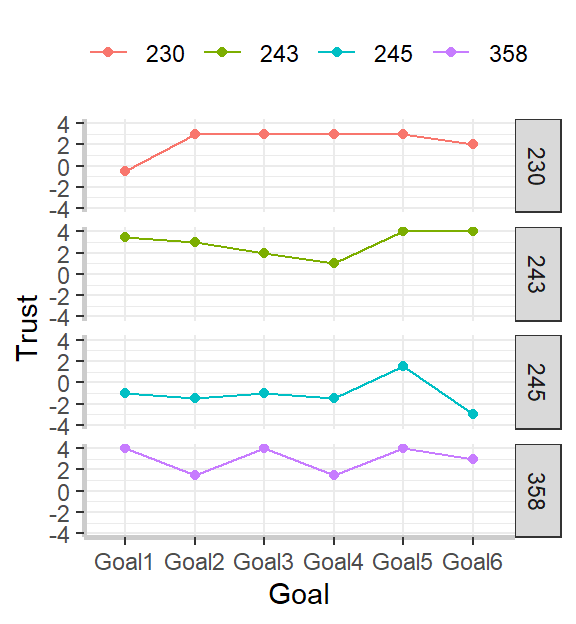
Next, I have to create the variables that indicate to what extent participants’ best friend’s most descriptive strength and weakness were to each of the six goals. Here is where we come across our first coding challenge.
Because this survey was idiographically-tailored, and participants could have identified anywhere from 6 to 25 goals, these data are what’s known as sparse. Sparse data has a lot of empty cells, and this was one of the sparsest data sets I’ve ever worked with. In this case, there was a single value for every participant scattered across 33 columns! I mean, take a look at this hot mess!
head(data1[, 1311:1345])
## Q14.1_1 Q14.1_1_TEXT Q14.1_2 Q14.1_2_TEXT Q14.1_3 Q14.1_3_TEXT Q14.1_4
## 1 4 NA NA NA NA NA NA
## 2 2 NA NA NA NA NA NA
## 3 NA NA NA NA 3 NA NA
## 4 NA NA NA NA NA NA NA
## 5 1 NA NA NA NA NA NA
## 6 NA NA NA NA NA NA 1
## Q14.1_4_TEXT Q14.1_5 Q14.1_5_TEXT Q14.1_6 Q14.1_7 Q14.1_8 Q14.1_9 Q14.1_10
## 1 NA NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA NA
## 4 NA NA NA NA 5 NA NA NA
## 5 NA NA NA NA NA NA NA NA
## 6 NA NA NA NA NA NA NA NA
## Q14.1_11 Q14.1_12 Q14.1_13 Q14.1_14 Q14.1_15 Q14.1_16 Q14.1_17 Q14.1_18
## 1 NA NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA NA
## 4 NA NA NA NA NA NA NA NA
## 5 NA NA NA NA NA NA NA NA
## 6 NA NA NA NA NA NA NA NA
## Q14.1_19 Q14.1_20 Q14.1_21 Q14.1_22 Q14.1_23 Q14.1_24 Q14.1_25 Q14.1_26
## 1 NA NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA NA
## 4 NA NA NA NA NA NA NA NA
## 5 NA NA NA NA NA NA NA NA
## 6 NA NA NA NA NA NA NA NA
## Q14.1_27 Q14.1_28 Q14.1_29 Q14.1_30
## 1 NA NA NA NA
## 2 NA NA NA NA
## 3 NA NA NA NA
## 4 NA NA NA NA
## 5 NA NA NA NA
## 6 NA NA NA NA
Here is the code I used to condense that sparse data into a set of variables so that every participants’ value was included in a single variable.
### Creating Goal Relevance Variables
## Most Important Goals ##########
# Goal 1 Strength
data1$Goal1StrRel<-(apply(data1[, 1311:1345], 1, function(x) x[!is.na(x)][1]))-1
Let’s see if that worked.
head(data1$Goal1StrRel:data1$Goal6StrRel)
## [1] 3 2
Great! Now we have condensed our first set of predictors, and it’s time to move onto the next set of variables.
The variables that contained participants’ trust in their best friend across each goal was similarly sparse, so I simply applied the same code to fix that here. However, the measures for goal-specific trust were a bit more complicated, so they require more code. Specifically, participants were first asked if they trusted their best friend or not for each goal, and then they were asked to what extent they trusted or distrusted their best friend, depending on whether they first selcted trust or distrust. Because we was a continuous measure for our analyses, we need to somehow combine those extent variables with the dichotomous measure. Below is the code for how I accomplished that.
### Creating Goal-Based Trust DVs ###
## Trust for Project 1
# Trust
data1$Goal1TrustDi<-(apply(data1[, 1731:1765], 1, function(x) x[!is.na(x)][1]))
# Extent Ss Trusts Best Friend for Project 1
data1$G1TrustExt<-as.numeric(data1$Q26.2)
# Extent Ss distrusts Best Friend for Project 1
data1$G1DistrustExt<-as.numeric(-data1$Q26.3)
# Lean Toward Trust vs Distrust
data1$G1TrustLean<-as.numeric(data1$Q26.4)
# Creating bipolar measure of Trust-Distrust
data1$Goal1TrustBP<-ifelse(data1$Goal1TrustDi==1,data1$G1TrustExt,
ifelse(data1$Goal1TrustDi==2,data1$G1DistrustExt,
ifelse(data1$G1TrustLean==1,1,
ifelse(data1$G1TrustLean==2,-1,NA))))
# Rely
data1$Goal1RelyDi<-(apply(data1[, 1769:1803], 1, function(x) x[!is.na(x)][1]))
# Extent Ss Trusts Best Friend for Project 1
data1$G1RelyExt<-as.numeric(data1$Q26.6)
# Extent Ss distrusts Best Friend for Project 1
data1$G1UnrelyDiExt<-as.numeric(-data1$Q26.7)
# Lean Toward Trust vs Distrust
data1$G1RelyLean<-as.numeric(data1$Q26.8)
# Creating bipolar measure of Trust-Distrust
data1$Goal1RelyBP<-ifelse(data1$Goal1RelyDi==1,data1$G1RelyExt,
ifelse(data1$Goal1RelyDi==2,data1$G1UnrelyDiExt,
ifelse(data1$G1RelyLean==1,1,
ifelse(data1$G1RelyLean==2,-1,NA))))
Whew!! That’s a lot! But we’re almost done. We have created our PIN, the continuous measure of goal mportance (for a manipulation check), the relevance of the best friend’s most descriptive strength and weakness to each goal, and the measure of goal-specific trust. All that is left is to create a subset of the data with only the variables that we need and to put it into the proper format.
Here, I subset the data and create the dataframme that I’ll use for plotting and my analyses
data2<-subset(data1,select=c(PIN:Goal1TrustDi,Goal1TrustBP,Goal1RelyDi,Goal1RelyBP,Goal2TrustDi,
Goal2TrustBP,Goal2RelyDi,Goal2RelyBP,Goal3TrustDi,Goal3TrustBP,Goal3RelyDi,
Goal3RelyBP,Goal4TrustDi,Goal4TrustBP,Goal4RelyDi,Goal4RelyBP,Goal5TrustDi,
Goal5TrustBP,Goal5RelyDi,Goal5RelyBP,Goal6TrustDi,Goal6TrustBP,Goal6RelyDi,
Goal6RelyBP))
Let’s check it to make sure everything worked properly
str(data2)
## 'data.frame': 399 obs. of 43 variables:
## $ PIN : Factor w/ 399 levels "1","2","3","4",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ g1Imp : num 9 9 9 7 7 9 7 9 9 9 ...
## $ g2Imp : num 8 9 9 9 8 7 5 7 9 8 ...
## $ g3Imp : num 8 9 9 9 7 9 8 9 9 7 ...
## $ g4Imp : num 6 7 9 4 3 7 6 6 5 5 ...
## $ g5Imp : num 6 7 9 2 2 5 7 4 4 5 ...
## $ g6Imp : num 5 1 9 6 2 7 3 3 6 3 ...
## $ Goal1StrRel : num 3 1 2 4 0 0 0 4 3 0 ...
## $ Goal1WeakRel: num 0 1 0 0 0 0 0 2 2 4 ...
## $ Goal2StrRel : num 2 0 3 4 0 0 0 4 2 0 ...
## $ Goal2WeakRel: num 1 0 2 0 0 0 0 2 1 4 ...
## $ Goal3StrRel : num 0 2 0 1 0 0 2 4 2 0 ...
## $ Goal3WeakRel: num 0 0 0 0 0 0 0 2 1 4 ...
## $ Goal4StrRel : num 0 2 2 4 0 4 0 2 0 3 ...
## $ Goal4WeakRel: num 1 0 2 0 0 2 0 0 0 0 ...
## $ Goal5StrRel : num 2 0 4 2 0 4 0 2 0 0 ...
## $ Goal5WeakRel: num 0 0 3 0 0 0 0 0 0 4 ...
## $ Goal6StrRel : num 2 2 4 0 0 3 0 0 1 2 ...
## $ Goal6WeakRel: num 0 1 2 0 0 0 0 0 1 0 ...
## $ Goal1TrustDi: int 1 2 1 1 1 3 1 1 1 1 ...
## $ Goal1TrustBP: num 4 -3 3 4 2 1 3 4 2 4 ...
## $ Goal1RelyDi : int 1 3 3 1 2 1 1 1 3 1 ...
## $ Goal1RelyBP : num 4 -1 1 4 -2 3 2 4 1 4 ...
## $ Goal2TrustDi: int 1 2 1 1 3 1 3 1 1 1 ...
## $ Goal2TrustBP: num 4 -3 4 4 1 3 1 4 2 4 ...
## $ Goal2RelyDi : int 1 2 1 1 3 1 1 1 3 2 ...
## $ Goal2RelyBP : num 4 -3 3 4 1 3 2 4 -1 -2 ...
## $ Goal3TrustDi: int 1 1 2 2 3 2 1 1 1 2 ...
## $ Goal3TrustBP: num 4 2 -1 -1 1 -2 3 4 3 -2 ...
## $ Goal3RelyDi : int 1 1 3 2 3 2 1 1 1 2 ...
## $ Goal3RelyBP : num 4 3 -1 -1 1 -3 3 4 2 -2 ...
## $ Goal4TrustDi: int 1 1 1 1 2 1 3 1 3 1 ...
## $ Goal4TrustBP: num 3 2 4 4 -4 4 -1 3 1 4 ...
## $ Goal4RelyDi : int 1 1 1 1 2 1 2 1 3 1 ...
## $ Goal4RelyBP : num 4 2 4 4 -4 4 -1 3 1 4 ...
## $ Goal5TrustDi: int 1 1 1 3 1 1 3 3 3 1 ...
## $ Goal5TrustBP: num 4 2 4 1 2 4 1 1 1 4 ...
## $ Goal5RelyDi : int 1 1 1 1 1 1 1 3 3 2 ...
## $ Goal5RelyBP : num 4 2 4 4 1 4 2 1 1 -2 ...
## $ Goal6TrustDi: int 1 1 1 1 1 1 1 1 1 1 ...
## $ Goal6TrustBP: num 4 2 4 3 2 2 2 3 3 4 ...
## $ Goal6RelyDi : int 1 1 1 1 1 1 1 1 1 1 ...
## $ Goal6RelyBP : num 4 2 4 3 2 3 3 4 2 4 ...
Perfect! Now, let’s arrange the variables for easier manipulation and set better names. In order to do this, we’ll need to convert our data from wide format to long format.
Most people are probably more familiar with wide format. In wide format, every column is a variable, and every row is a case or instance of the variable “participant.” In other words, each case represents a single participant. In long format, we stretch out our data so that each participant occupies multimple rows. In the end of this transformation, each row will be an instance or case of the variable “goal” so that every participant will occupy 6 rows, one for each of their three most and three least important goals.
### Arranging columns for easier manipulation
## Goal Importance
# Select vars
impData<-data2 %>% dplyr::select(tidyselect::vars_select(names(data2), dplyr::matches('Imp')))
# Add PIN
impData$PIN<-data2$PIN
# Wide to Long
impLong<-impData %>% gather(Goal,Importance,g1Imp:g6Imp)
# Rename factor levels
impLong$Goal<-mapvalues(impLong$Goal, from = c("g1Imp","g2Imp","g3Imp","g4Imp","g5Imp","g6Imp"),
to = c("Goal1","Goal2","Goal3","Goal4","Goal5","Goal6"))
## Relevance of strength to each project
# Select vars
strengthData<-data2 %>% dplyr::select(tidyselect::vars_select(names(data2), matches('StrRel')))
# Add PIN
strengthData$PIN<-data2$PIN
# Wide to Long
srelLong<-strengthData %>% gather(Goal,StRel,Goal1StrRel:Goal6StrRel)
# Rename factor levels
srelLong$Goal<-mapvalues(srelLong$Goal, from = c("Goal1StrRel","Goal2StrRel","Goal3StrRel","Goal4StrRel","Goal5StrRel","Goal6StrRel"),
to = c("Goal1","Goal2","Goal3","Goal4","Goal5","Goal6"))
## Relevance of weakness to each project
# Select vars
weakData<-data2 %>% dplyr::select(tidyselect::vars_select(names(data2), matches('WeakRel')))
# Add PIN
weakData$PIN<-data2$PIN
# Wide to Long
wrelLong<-weakData %>% gather(Goal,WeakRel,Goal1WeakRel:Goal6WeakRel)
# Rename factor levels
wrelLong$Goal<-mapvalues(wrelLong$Goal, from = c("Goal1WeakRel","Goal2WeakRel","Goal3WeakRel","Goal4WeakRel","Goal5WeakRel","Goal6WeakRel"),
to = c("Goal1","Goal2","Goal3","Goal4","Goal5","Goal6"))
## Trust best friend
# Select vars
trustData<-data2 %>% dplyr::select(tidyselect::vars_select(names(data2), matches('TrustBP')))
# Add PIN
trustData$PIN<-data2$PIN
# Wide to Long
tLong<-trustData %>% gather(Goal,Trust,Goal1TrustBP:Goal6TrustBP)
# Rename factor levels
tLong$Goal<-mapvalues(tLong$Goal, from = c("Goal1TrustBP","Goal2TrustBP","Goal3TrustBP","Goal4TrustBP","Goal5TrustBP","Goal6TrustBP"),
to = c("Goal1","Goal2","Goal3","Goal4","Goal5","Goal6"))
## Rely on best friend
# Select vars
relyData<-data2 %>% dplyr::select(tidyselect::vars_select(names(data2), matches('RelyBP')))
# Add PIN
relyData$PIN<-data2$PIN
# Wide to Long
rLong<-relyData %>% gather(Goal,Rely,Goal1RelyBP:Goal6RelyBP)
# Rename factor levels
rLong$Goal<-mapvalues(rLong$Goal, from = c("Goal1RelyBP","Goal2RelyBP","Goal3RelyBP","Goal4RelyBP","Goal5RelyBP","Goal6RelyBP"),
to = c("Goal1","Goal2","Goal3","Goal4","Goal5","Goal6"))
Now that we’ve created several smaller dataframes in long format, let’s merge them together to create a dataframe that’s in long format and has all of our variables. While we’re doing this, we will create a categorical variable that indicates whether a goal is one of the three most or three least important goals.
### Creating Working Long Data
# Importance and Trust
imp.trust<-merge(tLong,impLong,by=c("Goal","PIN"))
# Adding rely
imp.trust.rely<-merge(imp.trust,rLong,by=c("Goal","PIN"))
# Adding relevance to strength
imp.trust.rely.str<-merge(imp.trust.rely,srelLong,by=c("Goal","PIN"))
# Adding relevance to weakness
data3<-merge(imp.trust.rely.str,wrelLong,by=c("Goal","PIN"))
# Converting goal variable to factor for analyses
data3$Goal<-as.factor(data3$Goal)
# Adding Factor Indicating Most vs Least Important Projects
data3$impCat<-ifelse(data3$Goal=="Goal1", 1,
ifelse(data3$Goal=="Goal2", 1,
ifelse(data3$Goal=="Goal3", 1,
ifelse(data3$Goal=="Goal4", 0,
ifelse(data3$Goal=="Goal5", 0,
ifelse(data3$Goal=="Goal6", 0,NA))))))
# Converting to Factor
data3$impCat<-as.factor(data3$impCat)
data3$impCat<-factor(data3$impCat,
levels=c(0,1),
labels=c("Least Important","Most Important"))
Now let’s check our new dataframe to make sure all our variables are there and that they’re in the proper format.
str(data3)
head(data3)
tail(data3)
## 'data.frame': 2394 obs. of 8 variables:
## $ Goal : Factor w/ 6 levels "Goal1","Goal2",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ PIN : Factor w/ 399 levels "1","2","3","4",..: 1 10 100 101 102 103 104 105 106 107 ...
## $ Trust : num 4 4 3 1 -1 4 2 3 3 4 ...
## $ Importance: num 9 9 9 9 6 9 6 7 9 7 ...
## $ Rely : num 4 4 3 2 -3 4 2 4 1 4 ...
## $ StRel : num 3 0 0 0 0 3 3 2 3 0 ...
## $ WeakRel : num 0 4 0 0 1 0 0 3 0 1 ...
## $ impCat : Factor w/ 2 levels "Least Important",..: 2 2 2 2 2 2 2 2 2 2 ...
## Goal PIN Trust Importance Rely StRel WeakRel impCat
## 1 Goal1 1 4 9 4 3 0 Most Important
## 2 Goal1 10 4 9 4 0 4 Most Important
## 3 Goal1 100 3 9 3 0 0 Most Important
## 4 Goal1 101 1 9 2 0 0 Most Important
## 5 Goal1 102 -1 6 -3 0 1 Most Important
## 6 Goal1 103 4 9 4 3 0 Most Important
## Goal PIN Trust Importance Rely StRel WeakRel impCat
## 2389 Goal6 94 3 4 4 1 0 Least Important
## 2390 Goal6 95 -3 4 -3 0 0 Least Important
## 2391 Goal6 96 1 3 2 2 0 Least Important
## 2392 Goal6 97 -2 4 -1 0 0 Least Important
## 2393 Goal6 98 4 4 4 0 0 Least Important
## 2394 Goal6 99 -1 7 -2 0 0 Least Important
Now that we have the data in the appropriate format, we only have a couple more pre-processing steps. First, we need to center our predictor variables.
There are two ways I can choose to center my predictor variables, by participant or globally. Globally-centered variables will subtract the grand mean, or overall average of the variable, from each participant’s value. The end result will be that the average value of that variable across all participants will be 0. Participant-centered variables subtract each participant’s mean from each of their values. The end result of this process will be that the average for each participant on each variable is 0. Each of these centering strategies tells a different story, so it’s important to choose whichever one makes the most sense for your research question. In this case, participant-centered variables makes the most sense. So that’s what we’re going to do!
## Centering IVs by Ss
# Relevance to Strength
# Mean of Relevance to Strength
data3<-ddply(data3,.(PIN), plyr::mutate, rStrMean = mean(StRel))
# Participant-centered Relevance to Strength
data3$StrRelC<-data3$StRel-data3$rStrMean
# Globally-centered Relevance to Strength
data3$StrRel_GlobC <- scale(data3$StRel, scale = FALSE)[,]
Now that we’ve centered our predictors, let’s check whether our two questions that are to make up our composite measure of goal-specific trust are sufficiently correlated. In other words, I want to average the responses to the question “To what extent would you trust your best friend” with the responses to the question “To what extent would you be willing to rely on your best friend?” However, if these items do not actually measure the same thing (i.e., the correlation is really low), then I shouldn’t average them together. So let’s look real quick.
cor.test(data3$Trust,data3$Rely, use = "pairwise.complete.obs")
##
## Pearson's product-moment correlation
##
## data: data3$Trust and data3$Rely
## t = 62.764, df = 2378, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.7740460 0.8043255
## sample estimates:
## cor
## 0.7896661
Ok. They’re correlated at about 0.80, which is not the best, but it does fall within the range that most consider appropriate for averaging. So, now I’ll do that here.
data3$trustRely <- (data3$Trust+data3$Rely)/2
Perfect! Now we’re ready to explore and analyzing our data!
Analyses
Now that we’ve graphed our data and gotten insight into our variables’ distributions and the relationships between our predictor and criterion variables, it’s time to run statistical analyses to formally test our hypotheses.
The analyses that I will do below are linear multilevel (or mixed effects) models (MLMs). These analyses will allow me to model the random variance that is caused by our participants reporting different average levels of trust in their best friend (random intercept) and different relationships betweeen goal importance and goal-specific trust (random slope).
As a side note, the most appropriate analyses for these data are actually ordinal logistic multilevel models. The criterion variable, goal-specific trust, is on an ordinal scale. Ordinal scales are where the distance between scale points are not even. By contrast, in interval or ratio scales, the distance between scale points is the same. An example of an interval scale is temperature in degrees Fahrenheit. The difference between 1\(^\circ\) and 2\(^\circ\) Fahrenheit is the same as the difference between 101\(^\circ\) and 102\(^\circ\) Fahrenheit. By contrast, is the difference between “slightly trust” and “moderately trust” the same as the difference between “moderately trust” and “very much trust?” I don’t know, but probably not. Technically, linear MLMs require interval or ratio criterion variables whereas ordinal logistic MLMs require ordinal criterion variables. However, I ran both sets of analyses, and the conclusions remain the same. Consequently, I demonstrate linear MLMs here because they are generally easier to understand.
These analyses are a bit complicated and require us to carefully monitor changes in our output as a funciton of changes in our fixed and random effects. I will explain each step.
Random Effects
The first step in running MLMs is to examine your random structure. To do this, we will include only the criterion variable and an intercept in our model and systematically change our random effects. This part might be a bit easier to understand while doing it than me explaining it, so let’s just dive right in.
In this first model, I am going to use what’s called the maximal random structure. The maximal structure includes the random intercept and the random slope, and is our best model at reducing our Type I error rate (which is the probability of incorrectly saying there is a real effect when there is in fact no effect).
max_random <- lmer(Importance ~ 1
+ (1+dummy(impCat)|PIN), data = data3, REML=F)
summary(max_random)
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Importance ~ 1 + (1 + dummy(impCat) | PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 9518.6 9547.5 -4754.3 9508.6 2389
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -4.7603 -0.5828 0.1264 0.7316 3.3925
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## PIN (Intercept) 10.647 3.263
## dummy(impCat) 13.095 3.619 -0.99
## Residual 1.827 1.352
## Number of obs: 2394, groups: PIN, 399
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 7.47523 0.03965 398.99978 188.5 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The first thing you should note is the warning that the model failed to converge. This means that the maximum likelihood estimation process (beyond the scope of this explanation) failed. A wise person once told me that a model that does not work cannot be the correct model. Although we’re getting numbers here, it’s probably best to reduce our random structure. The second thing to note is that the correlaiton between the random intercept and the random slope is very high (-0.99). A perfect correlation (+/- 1.00) is very bad for our model, so that gives us further reason to reduce our random structure.
The very first change I like to make is to block the correlation between the random slope and intercept. This removes a single feature from our random effects, so it is a desirable first step. To do this, I’m just going to add another | in the random effects portion of the model, like this.
no_cor_random <- lmer(Importance ~ 1
+ (1+dummy(impCat)||PIN), data = data3, REML=F)
summary(no_cor_random)
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Importance ~ 1 + (1 + dummy(impCat) || PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 10056.3 10079.5 -5024.2 10048.3 2390
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.8756 -0.5501 0.1163 0.5550 3.2275
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN (Intercept) 1.822 1.350
## PIN.1 dummy(impCat) 11.937 3.455
## Residual 1.868 1.367
## Number of obs: 2394, groups: PIN, 399
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 4.69898 0.07781 395.17704 60.39 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
That worked! Notice how we didn’t get anymore errors? This random structure does seem to fit our data a bit better. I also want you to notice that the residual variance increased ever so slightly. That’s because we removed a random effect that was accounting for some of the variance (the correlation between the random slope and intercept). It’s important to keep a close eye on your residuals as you explore different model fits.
Depending on the training you’ve received in MLMs, some would stop examining the random structure here. The argument goes that every reduction in the random structure has a potential (or inevitable) increase in the Type I error rate. However, I use parsimonious fitting (Bates, Kliegl, Vasishth, & Baayen, 2015) to systematically reduce the random terms and find the simplest model that does not sacrifice model fit. To do so, I will remove random effects one at a time and see the potential change in the residual of the model. The moment a model fits significantly worse, as determined by a Chi-square, I will stop and keep the more complex model. This process can be long, and it is indeed long for these data, so I will only show the first step.
In this first step, I am going to remove the random intercept. To execute this step, I simply need to change the “1” in my random effects portion to “0.” Let’s see what happens.
no_intercept_random <- lmer(Importance ~ 1
+ (0+dummy(impCat)||PIN), data = data3, REML=F)
summary(no_intercept_random)
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Importance ~ 1 + (0 + dummy(impCat) || PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 10423.2 10440.5 -5208.6 10417.2 2391
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.9456 -0.4826 0.0856 0.6538 2.3584
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN dummy(impCat) 9.239 3.04
## Residual 3.098 1.76
## Number of obs: 2394, groups: PIN, 399
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 4.849e+00 4.849e-02 2.277e+03 100 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Notice that the residual variance increased by a lot?! That probably means this model is not as good a fit. Let’s formally test our intuition.
anova(no_cor_random, no_intercept_random)
## Data: data3
## Models:
## no_intercept_random: Importance ~ 1 + (0 + dummy(impCat) || PIN)
## no_cor_random: Importance ~ 1 + (1 + dummy(impCat) || PIN)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## no_intercept_random 3 10423 10440 -5208.6 10417
## no_cor_random 4 10056 10080 -5024.2 10048 368.85 1 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
As expected, the no intercepts model fits significantly worse. Normally, that would mean that I would keep the more complex model. However, when I added in the main effects, those models failed to converge with the more complex random structures. After hours of pouring through many many models, it turned out that the simplest model was the only one that converged across all analyses. Because you must have the same random structure to compare between models, that is the structure I will use here. The final random structure, then, only includes a random intercept.
Now that we’ve examined our random structure, let’s start actually testing our hypotheses.
Fixed effects
In MLMs, fixed effects refer to the effects of interest. In other words, our fixed effects are the relationships between our predictor variables and our criterion variable. In the case of this study, our fixed effects are goal importance, relevance to strength, relevance to weakness, and the two-way interactions between goal importance and the two relevance variables. We will need four different models to examine all of our hypotheses, starting with a model that only includes the main effects of our predictor variables.
main_effects <- lmer(trustRely ~ WeakRelC + StrRelC + impCat
+ (1|PIN), data = data3, REML=F)
summary(main_effects)
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: trustRely ~ WeakRelC + StrRelC + impCat + (1 | PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 9781.3 9815.9 -4884.7 9769.3 2328
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3030 -0.5081 0.1819 0.6311 2.3093
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN (Intercept) 1.081 1.040
## Residual 3.200 1.789
## Number of obs: 2334, groups: PIN, 389
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 1.721e+00 7.439e-02 6.765e+02 23.128 <2e-16 ***
## WeakRelC 8.599e-02 4.559e-02 1.945e+03 1.886 0.0594 .
## StrRelC 4.748e-01 3.379e-02 1.945e+03 14.050 <2e-16 ***
## impCatMost Important 1.708e-01 7.439e-02 1.945e+03 2.296 0.0218 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) WekRlC StrRlC
## WeakRelC 0.002
## StrRelC 0.045 -0.281
## impCtMstImp -0.500 -0.003 -0.089
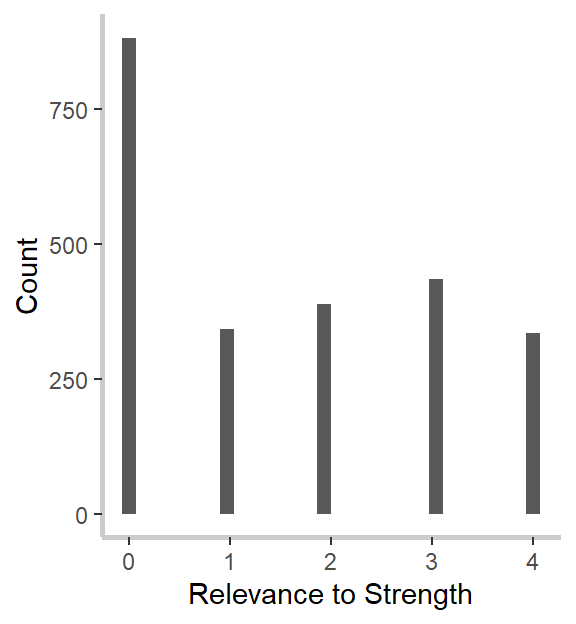
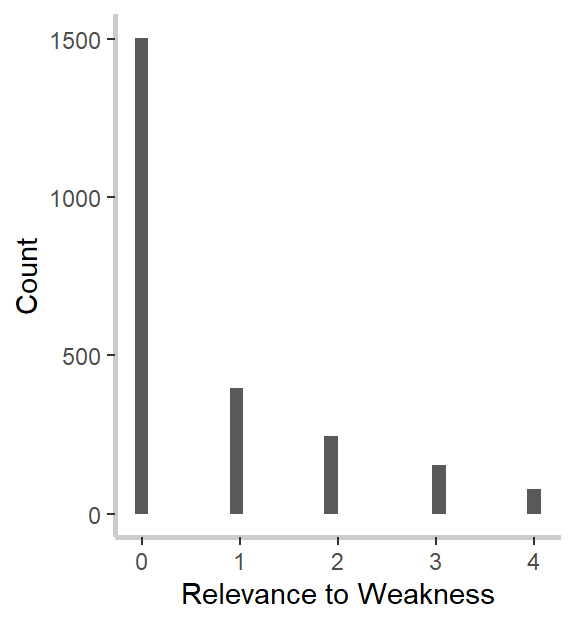
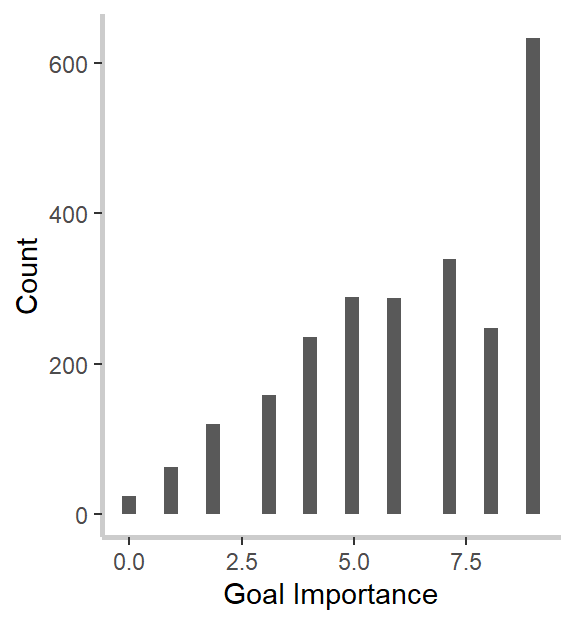
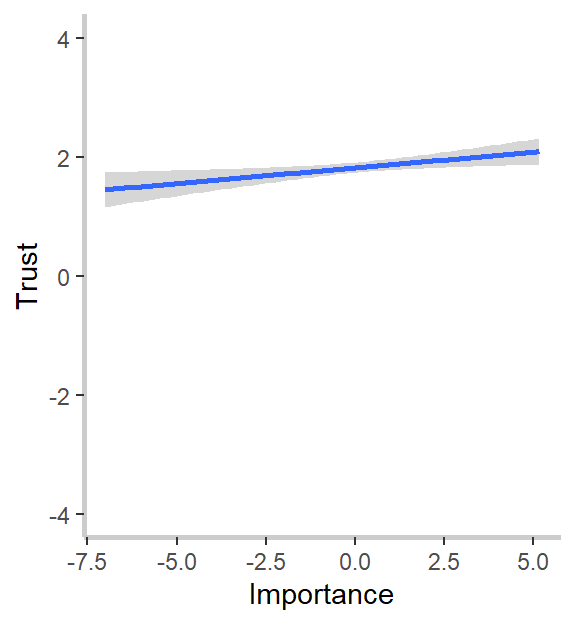
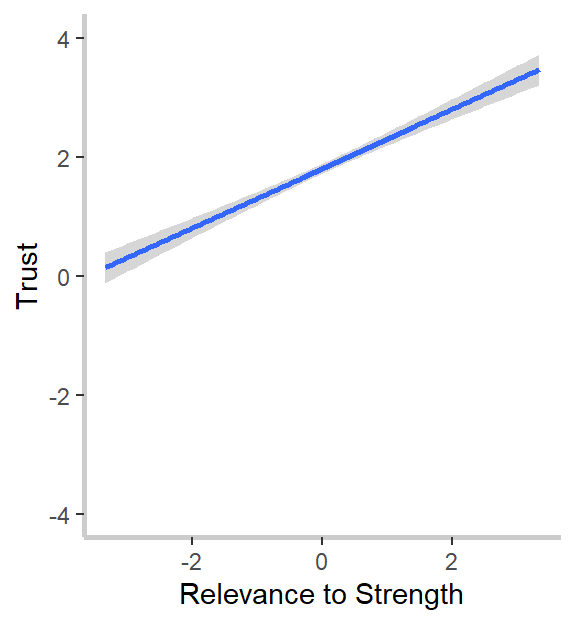
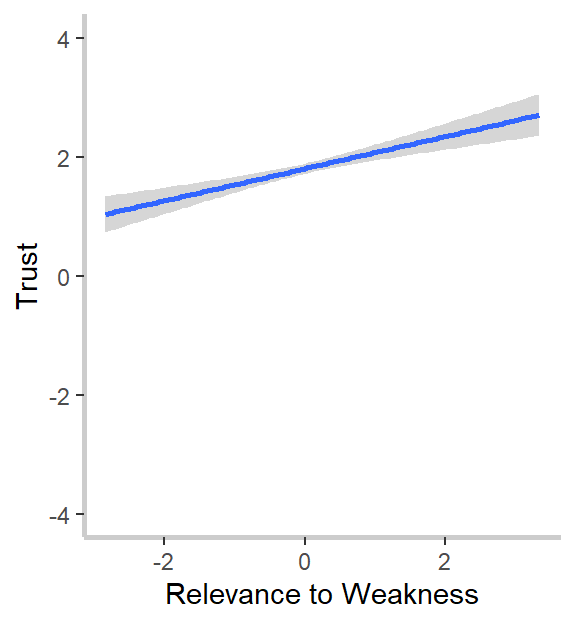
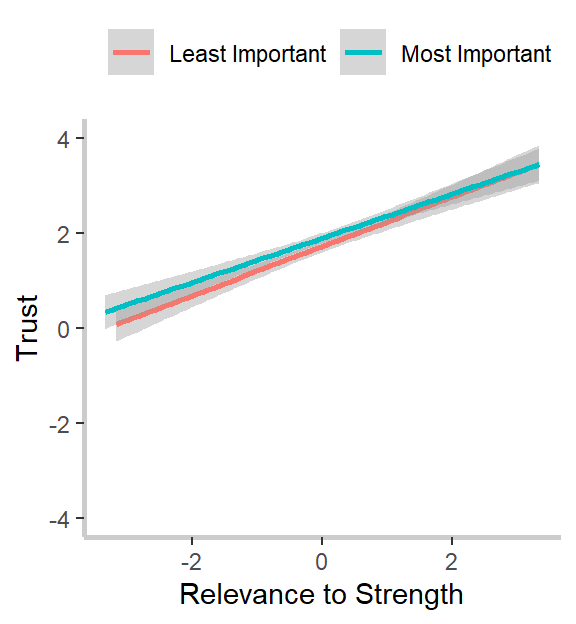
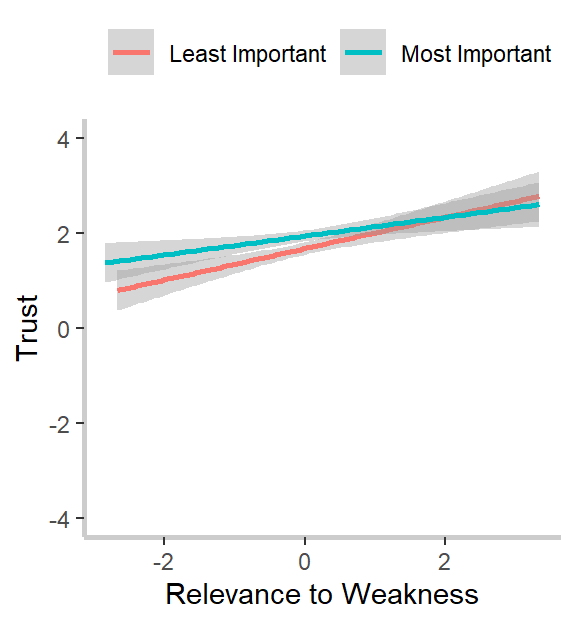
What do we notice? First, our relevance to strength measure strongly and significantly predicts goal-specific trust. This was the effect we noticed in our graphs above and confirms both our hypothesis and intuitions from the graph. Second, and in line with the graphs but against our hypothesis, goal importance is a significant and positive predictor of trust, and the relevance to weakness is a marginally (ugh, I hate that word too) significant and positive predictor of trust. I’m not going to go through the implications for the theory here, so I encourage you to read my dissertation, if you’re interested. :)
Next, let’s add each of the interactions in one-at-a-time. We will test whether the more complex model fits the data better than the simpler model after each step
## Adding interaction between Strength and Importance
strength_importance <- lmer(trustRely ~ WeakRelC + StrRelC*impCat
+ (1|PIN), data=data3, REML=F)
summary(strength_importance)
# The interaction is negative but not significant
anova(main_effects, strength_importance)
# Not a significant improvement in model fit
## Adding interaction between Weakness and Importance
weakness_importance<-lmer(trustRely ~ WeakRelC*impCat + StrRelC
+ (1|PIN), data=data3, REML=F)
summary(weakness_importance)
# The interaction is not significant
anova(main_effects, weakness_importance)
# Not a significant improvement in model fit
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: trustRely ~ WeakRelC + StrRelC * impCat + (1 | PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 9782.8 9823.1 -4884.4 9768.8 2327
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3002 -0.5165 0.1820 0.6289 2.3274
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN (Intercept) 1.081 1.040
## Residual 3.199 1.789
## Number of obs: 2334, groups: PIN, 389
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 1.72340 0.07448 679.18622 23.139 <2e-16
## WeakRelC 0.08552 0.04559 1945.06710 1.876 0.0608
## StrRelC 0.50142 0.04871 2126.10309 10.295 <2e-16
## impCatMost Important 0.17086 0.07438 1945.00058 2.297 0.0217
## StrRelC:impCatMost Important -0.05391 0.07093 2254.37899 -0.760 0.4474
##
## (Intercept) ***
## WeakRelC .
## StrRelC ***
## impCatMost Important *
## StrRelC:impCatMost Important
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) WekRlC StrRlC impCMI
## WeakRelC 0.001
## StrRelC 0.067 -0.205
## impCtMstImp -0.499 -0.003 -0.061
## StrRlC:mCMI -0.051 0.013 -0.720 -0.002
## Data: data3
## Models:
## main_effects: trustRely ~ WeakRelC + StrRelC + impCat + (1 | PIN)
## strength_importance: trustRely ~ WeakRelC + StrRelC * impCat + (1 | PIN)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## main_effects 6 9781.3 9815.9 -4884.7 9769.3
## strength_importance 7 9782.8 9823.1 -4884.4 9768.8 0.5775 1 0.4473
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: trustRely ~ WeakRelC * impCat + StrRelC + (1 | PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 9783.3 9823.6 -4884.7 9769.3 2327
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3006 -0.5072 0.1825 0.6291 2.3089
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN (Intercept) 1.08 1.039
## Residual 3.20 1.789
## Number of obs: 2334, groups: PIN, 389
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 1.72072 0.07439 675.67170 23.132 <2e-16
## WeakRelC 0.09373 0.06581 2150.93808 1.424 0.1545
## impCatMost Important 0.17079 0.07439 1944.14933 2.296 0.0218
## StrRelC 0.47470 0.03380 1944.19712 14.047 <2e-16
## WeakRelC:impCatMost Important -0.01581 0.09693 2284.15420 -0.163 0.8704
##
## (Intercept) ***
## WeakRelC
## impCatMost Important *
## StrRelC ***
## WeakRelC:impCatMost Important
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) WekRlC impCMI StrRlC
## WeakRelC 0.012
## impCtMstImp -0.500 -0.001
## StrRelC 0.045 -0.202 -0.089
## WkRlC:mpCMI -0.016 -0.721 -0.002 0.011
## Data: data3
## Models:
## main_effects: trustRely ~ WeakRelC + StrRelC + impCat + (1 | PIN)
## weakness_importance: trustRely ~ WeakRelC * impCat + StrRelC + (1 | PIN)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## main_effects 6 9781.3 9815.9 -4884.7 9769.3
## weakness_importance 7 9783.3 9823.6 -4884.7 9769.3 0.0265 1 0.8706
In contrast to our hypotheses, neither interaction is significant. However, we have one final model to test before we go home. We still need to test the model with both interactions included.
## Adding both interactions for completeness
full_model <- lmer(trustRely ~ WeakRelC*impCat + StrRelC*impCat
+ (1|PIN), data=data3, REML=F)
summary(full_model)
# Neither interaction is significant
anova(strength_importance, full_model)
anova(weakness_importance, full_model)
# Not a significant improvement in model fit over either singular interaction models
## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: trustRely ~ WeakRelC * impCat + StrRelC * impCat + (1 | PIN)
## Data: data3
##
## AIC BIC logLik deviance df.resid
## 9784.8 9830.8 -4884.4 9768.8 2326
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3009 -0.5184 0.1817 0.6294 2.3279
##
## Random effects:
## Groups Name Variance Std.Dev.
## PIN (Intercept) 1.082 1.040
## Residual 3.199 1.789
## Number of obs: 2334, groups: PIN, 389
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 1.723e+00 7.449e-02 6.777e+02 23.137 <2e-16
## WeakRelC 8.304e-02 6.734e-02 2.156e+03 1.233 0.2177
## impCatMost Important 1.709e-01 7.437e-02 1.944e+03 2.297 0.0217
## StrRelC 5.019e-01 4.982e-02 2.130e+03 10.075 <2e-16
## WeakRelC:impCatMost Important 5.046e-03 1.009e-01 2.282e+03 0.050 0.9601
## impCatMost Important:StrRelC -5.493e-02 7.382e-02 2.251e+03 -0.744 0.4569
##
## (Intercept) ***
## WeakRelC
## impCatMost Important *
## StrRelC ***
## WeakRelC:impCatMost Important
## impCatMost Important:StrRelC
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) WekRlC impCMI StrRlC WRC:CI
## WeakRelC 0.002
## impCtMstImp -0.499 -0.001
## StrRelC 0.066 -0.290 -0.060
## WkRlC:mpCMI -0.002 -0.736 -0.001 0.211
## impCtMI:SRC -0.048 0.213 -0.001 -0.735 -0.277
## Data: data3
## Models:
## strength_importance: trustRely ~ WeakRelC + StrRelC * impCat + (1 | PIN)
## full_model: trustRely ~ WeakRelC * impCat + StrRelC * impCat + (1 | PIN)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## strength_importance 7 9782.8 9823.1 -4884.4 9768.8
## full_model 8 9784.8 9830.8 -4884.4 9768.8 0.0025 1 0.9602
## Data: data3
## Models:
## weakness_importance: trustRely ~ WeakRelC * impCat + StrRelC + (1 | PIN)
## full_model: trustRely ~ WeakRelC * impCat + StrRelC * impCat + (1 | PIN)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## weakness_importance 7 9783.3 9823.6 -4884.7 9769.3
## full_model 8 9784.8 9830.8 -4884.4 9768.8 0.5534 1 0.4569
The full model is not an improvement over either single interaction models.
LS0tDQp0aXRsZTogIkNvbnRleHR1YWwgVHJ1c3QgU3R1ZHkiDQpvdXRwdXQ6DQogIGh0bWxfZG9jdW1lbnQ6DQogICAgaW5jbHVkZXM6DQogICAgICAgaW5faGVhZGVyOiBHQV9zY3JpcHQuaHRtbA0KICAgIGNvZGVfZG93bmxvYWQ6IHllcw0KICAgIGZvbnRzaXplOiA4cHQNCiAgICBoaWdobGlnaHQ6IHRleHRtYXRlDQogICAgbnVtYmVyX3NlY3Rpb25zOiBubw0KICAgIHRoZW1lOiBjb3Ntbw0KICAgIHRvYzogeWVzDQogICAgdG9jX2Zsb2F0Og0KICAgICAgY29sbGFwc2VkOiBubw0KLS0tDQoNCmBgYHtyIHNldHVwLCBpbmNsdWRlPUZBTFNFfQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGNhY2hlID0gVFJVRSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldChlY2hvID0gVFJVRSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldChtZXNzYWdlID0gRkFMU0UpDQprbml0cjo6b3B0c19jaHVuayRzZXQod2FybmluZyA9ICBGQUxTRSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldChmaWcud2lkdGg9My4yNSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldChmaWcuaGVpZ2h0PTIuNzUpDQprbml0cjo6b3B0c19jaHVuayRzZXQoZmlnLmFsaWduPSdjZW50ZXInKSANCmtuaXRyOjpvcHRzX2NodW5rJHNldChyZXN1bHRzPSdob2xkJykgDQpgYGANCg0KYGBge3IsIGVjaG89RkFMU0UsIHdhcm5pbmc9RkFMU0V9DQpsaWJyYXJ5KHBzeWNoKQ0KbGlicmFyeShsbWU0KQ0KbGlicmFyeShwbHlyKQ0KbGlicmFyeSh0aWR5dmVyc2UpDQpsaWJyYXJ5KGdncGxvdDIpDQpsaWJyYXJ5KGdnc3RhdHNwbG90KQ0KbGlicmFyeShkYXRhLnRhYmxlKQ0KbGlicmFyeShnbW9kZWxzKQ0KbGlicmFyeSh0ZXhyZWcpDQpsaWJyYXJ5KGxtZXJUZXN0KQ0KbGlicmFyeShhcGFUYWJsZXMpDQoNCmBgYA0KDQpgYGB7ciwgZWNobz1GQUxTRSwgd2FybmluZz1GQUxTRX0NCnNldHdkKCJDOi9Vc2Vycy90aW1vdC9PbmVEcml2ZS9Eb2N1bWVudHMvR2l0SHViL1RpbV9DYXJzZWwuZ2l0aHViLmlvLyIpDQpkYXRhMTwtcmVhZC5jc3YoIkRpc3NlcnRhdGlvbl9JZGlvVHJ1c3QuY3N2IiwgaGVhZGVyID0gVCwgbmEuc3RyaW5ncyA9IGMoIiIpKQ0KYGBgDQoNCg0KIyBCcmllZiBSYXRpb25hbGUgb2YgbXkgc3R1ZHkNCkludGVycGVyc29uYWwgdHJ1c3QgaXMgYW4gaW1wb3J0YW50IGZhY2V0IG9mIHJlbGF0aW9uc2hpcHMsIGJ1dCBjdXJyZW50IHRoZW9yaWVzIGFuZCByZXNlYXJjaCBwYXJhZGlnbXMgb24gaW50ZXJwZXJzb25hbCB0cnVzdCBtYXkgYmUgaW5jb21wbGV0ZS4gVHJ1c3QgaGFzIHRyYWRpdGlvbmFsbHkgYmVlbiBzdHVkaWVkIGFzIGVpdGhlciBhIHRyYWl0IG9mIHRoZSBpbmRpdmlkdWFsIG9yIGEgZmFjZXQgb2YgYSBzcGVjaWZpYyByZWxhdGlvbnNoaXAgYmV0d2VlbiB0d28gcGVvcGxlLiBBbHRob3VnaCBib3RoIGFwcHJvYWNoZXMgaGlnaGxpZ2h0IGRpZmZlcmVudCBhbmQgaW1wb3J0YW50IGFzcGVjdHMgb2YgdGhlIHBzeWNob2xvZ3kgb2YgdHJ1c3QsIGJvdGggYXBwcm9hY2hlcyBhcmUgbGltaXRlZCBpbiB0aGVpciBhYmlsaXR5IHRvIHVuY292ZXIgbW9yZSBtaW51dGUgZHluYW1pY3MuIA0KDQpJbiBteSBkaXNzZXJ0YXRpb24sIEkgcHJvcG9zZWQgYW5kIHRlc3RlZCBhIGdvYWwtc3BlY2lmaWMgdGhlb3J5IG9mIGludGVycGVyc29uYWwgdHJ1c3QsIHRoZSBJbnRlcmRlcGVuZGVudCBHb2FsIE1vZGVsIG9mIEludGVycGVyc29uYWwgVHJ1c3QgKElHTSkuIEkgYXJndWVkIHRoYXQgdGhlIHRydXN0IGJldHdlZW4gdHdvIHBlb3BsZSB2YXJpZXMgYWNyb3NzIHRoZSBpbnRlcmRlcGVuZGVudCBnb2FscyB0aGF0IGFyZSBzaGFyZWQgd2l0aGluIGEgcmVsYXRpb25zaGlwIGFuZCB0aGF0IHRoaXMgdmFyaWFiaWxpdHkgaXMgaW1wb3J0YW50IGZvciB1bmRlcnN0YW5kaW5nIGludGVycGVyc29uYWwgcmVsYXRpb25zaGlwcy4gDQoNClRlc3RpbmcgdGhlIGh5cG90aGVzZXMgZGVyaXZlZCBmcm9tIHRoZSBJR00gcmVxdWlyZWQgYSBtZXRob2RvbG9neSBzZW5zaXRpdmUgdG8gdGhlIGlkaW9zeW5jcmF0aWMgZ29hbHMgYW5kIHJlbGF0aW9uc2hpcHMgb2YgdGhlIHBhcnRpY2lwYW50cy4gVG8gdGhpcyBlbmQsIEkgZW1wbG95ZWQgYSBub3ZlbCBhbmQgaWRlb2dyYXBoaWNhbGx5LXRhaWxvcmVkIHN1cnZleSBpbiB3aGljaCBwYXJ0aWNpcGFudHMgZGVzY3JpYmVkIHRoZWlyIGN1cnJlbnQgZ29hbHMgYW5kIGJlc3QgZnJpZW5kLiBBZnRlciBwYXJ0aWNpcGFudHMgZGVzY3JpYmVkIHRoZWlyIGdvYWxzIGFuZCBiZXN0IGZyaWVuZCwgdGhleSB3ZXJlIGFza2VkIHRvIHdoYXQgZXh0ZW50IHRoZXkgd291bGQgdHJ1c3QgdGhlaXIgYmVzdCBmcmllbmQgYWNyb3NzIHNvbWUgb2YgdGhlaXIgbW9zdCBhbmQgbGVhc3QgaW1wb3J0YW50IGdvYWxzLiAgDQoNCk9uIHRoaXMgcGFnZSwgSSB3aWxsIHdhbGsgeW91IHRocm91Z2ggdGhlIGxvZ2ljIGFuZCBtYWluIGZpbmRpbmdzIG9mIG15IGRpc3NlcnRhdGlvbiwgaW5jbHVkaW5nIGFsbCBuZWNlc3NhcnkgZGF0YSBwcmUtcHJvY2Vzc2luZyBzdGVwcyBhbmQgbXkgYW5hbHlzZXMuIElmIHlvdSdyZSBpbnRlcmVzdGVkIGluIGEgbW9yZSBkZXRhaWxlZCBhY2NvdW50IG9mIG15IHRoZW9yeSwgaHlwb3RoZXNlcywgYW5kIG1ldGhvZHMsIHRoZW4gSSBlbmNvdXJhZ2UgeW91IHRvIHJlYWQgbXkgZGlzc2VydGF0aW9uIFtoZXJlXShDYXJzZWxfMjAyMF9JbnRlcmRlcGVuZGVudCBnb2FsIG1vZGVsIG9mIHRydXN0LnBkZikNCjxici8+PGJyLz48YnIvPjxici8+DQoNCg0KDQoNCiMgSHlwb3RoZXNlcw0KLSBUaGUgZmlyc3QgaHlwb3RoZXNpcyBvZiB0aGUgcHJlc2VudCBzdHVkeSBpcyB0aGF0IGludGVycGVyc29uYWwgdHJ1c3Qgd2lsbCBpbmNyZWFzZSBhcyB0aGUgcmVsZXZhbmNlIG9mIGEgYmVzdCBmcmllbmTigJlzIHN0cmVuZ3RoIHRvIGEgZ2l2ZW4gdGFzayBpbmNyZWFzZXMsIGFuZCBpbnRlcnBlcnNvbmFsIHRydXN0IHdpbGwgZGVjcmVhc2UgYXMgdGhlIHJlbGV2YW5jZSBvZiBhIGJlc3QgZnJpZW5k4oCZcyB3ZWFrbmVzcyB0byBhIGdpdmVuIHRhc2sgaW5jcmVhc2VzLiANCg0KLSBUaGUgc2Vjb25kIGh5cG90aGVzaXMgb2YgdGhlIHByZXNlbnQgc3R1ZHkgaXMgdGhhdCBpbmRpdmlkdWFscyB3aWxsIHBsYWNlIGxvd2VyIHRydXN0IGluIGFub3RoZXIgcGVyc29uIG9uIGF2ZXJhZ2UgYWNyb3NzIGEgcmFuZ2Ugb2YgaGlnaGx5IGltcG9ydGFudCBnb2FscyByZWxhdGl2ZSB0byBnb2FscyBvZiBsb3dlciBpbXBvcnRhbmNlLg0KDQotIFRoZSB0aGlyZCBoeXBvdGhlc2lzIG9mIHRoZSBwcmVzZW50IHN0dWR5IGlzIHRoYXQgZm9yIG1vcmUgaW1wb3J0YW50IGdvYWxzLCBwZW9wbGUgd2lsbCBiZSBtb3JlIGxpa2VseSB0byB0cnVzdCBhbiBpbXBvcnRhbnQgcmVsYXRpb25hbCBwYXJ0bmVyIChlLmcuLCBiZXN0IGZyaWVuZCkgaWYgdGhleSBiZWxpZXZlIHRoZSB0cnVzdGVl4oCZcyBzdHJlbmd0aHMgYXJlIHJlbGV2YW50IHRvIHRoZSB0YXNrIGFuZCBsZXNzIGxpa2VseSB0byB0cnVzdCB0aGF0IHJlbGF0aW9uYWwgcGFydG5lciBpZiB0aGV5IGJlbGlldmUgdGhlIHRydXN0ZWXigJlzIHdlYWtuZXNzZXMgYXJlIHJlbGV2YW50IHRvIHRoZSB0YXNrLiBGb3IgZ29hbHMgdGhhdCBhcmUgbGVzcyBpbXBvcnRhbnQsIGJlbGllZnMgYWJvdXQgdGhlIHRydXN0ZWXigJlzIHN0cmVuZ3RocyBhbmQgd2Vha25lc3NlcyB3aWxsIGJlIGxlc3MgcmVsZXZhbnQuDQo8YnIvPjxici8+PGJyLz48YnIvPg0KDQoNCg0KDQojIFN1cnZleSBNZXRob2RvbG9neSBPdmVydmlldw0KSW4gb3JkZXIgdG8gdW5kZXJzdGFuZCBhbnkgYW5hbHlzaXMsIGl0J3MgaW1wb3J0YW50IHRvIGZpcnN0IHVuZGVyc3RhbmQgdGhlIGRhdGEgZ2VuZXJhdGlvbiBwcm9jZXNzLiBJbiB0aGUgY2FzZSBvZiB0aGVzZSBkYXRhLCBwYXJ0aWNpcGFudHMgY29tcGxldGVkIGFuIGlkaW9ncmFwaGljYWxseS10YWlsb3JlZCBzdXJ2ZXkuIA0KDQpBIHRyYWRpdGlvbmFsIHN1cnZleSB1c2VzIHdoYXQncyBjYWxsZWQgYSAqKm5vbW90aGV0aWMqKiBhcHByb2FjaCwgd2hpY2ggYWltcyB0byB1bmRlcnN0YW5kIGhvdyBncm91cHMgb2YgcGVvcGxlIGFjdC4gVGhlc2UgYXJlIHRoZSBraW5kcyBvZiBzdXJ2ZXlzIHBlb3BsZSB0YWtlIGFsbCB0aGUgdGltZS4gRm9yIGV4YW1wbGUsIGlmIHlvdSd2ZSBldmVyIGNvbXBsZXRlZCBhIGN1c3RvbWVyIHNhdGlzZmFjdGlvbiBzdXJ2ZXkgdGhhdCBhc2tlZCB5b3UgcXVlc3Rpb25zIGxpa2UgIk9uIGEgc2NhbGUgb2YgMSB0byA1LCBob3cgc2F0aXNmaWVkIHdlcmUgeW91IHdpdGggdGhlIHNlcnZpY2UgeW91IHJlY2VpdmVkPyIsIHRoZW4geW91IGhhdmUgY29tcGxldGVkIGEgbm9tb3RoZXRpY2FsbHktZGVzaWduZWQgc3VydmV5LiANCg0KQnkgY29udHJhc3QsIGFuICoqaWRpb2dyYXBoaWMqKiBhcHByb2FjaCBhaW1zIHRvIHVuZGVyc3RhbmQgdGhlIGlkaW9zeW5jcmFjaWVzIG9mIHRoZSBpbmRpdmlkdWFsLiBBbiBleGFtcGxlIG9mIGFuIGlkaW9ncmFwaGljYWxseS1kZXNpZ25lZCBjdXN0b21lciBzYXRpc2ZhY3Rpb24gc3VydmV5IHF1ZXN0aW9uIG1pZ2h0IGJlIHNvbWV0aGluZyBtb3JlIGFsb25nIHRoZSBsaW5lcyBvZiAiV2hhdCB3YXMgdGhlIG1vc3QgaW1wb3J0YW50IHBhcnQgb2YgdGhlIHNlcnZpY2UgeW91IHJlY2VpdmVkIGZvciB3aHkgeW91IGdhdmUgdGhlIHJhdGluZyB5b3UgZGlkPyIsIHdpdGggYW4gb3Blbi1lbmRlZCB0ZXh0IGJveCBmb3IgcGVvcGxlIHRvIHdyaXRlIGluIHRoZWlyIHJlc3BvbnNlLg0KPGJyLz48YnIvPjxici8+DQoNCiMjIE1ldGhvZA0KSW4gaWRpb2dyYXBoaWNhbGx5LXRhaWxvcmVkIHN1cnZleSBmcm9tIHdoaWNoIHdlIGdvdCBvdXIgZGF0YSwgcGFydGljaXBhbnRzIHdlcmUgYXNrZWQgYWJvdXQgdGhlaXIgZ29hbHMgYW5kIHRoZWlyIGJlc3QgZnJpZW5kLiBTcGVjaWZpY2FsbHksIHBhcnRpY2lwYW50cyBmaXJzdCBsaXN0ZWQgdGhlIGdvYWxzIHRoZXkgd2VyZSBjdXJyZW50bHkgcHVyc3VpbmcsIGFuZCB0aGVuIHRoZXkgd2VyZSBhc2tlZCB0byBzZWxlY3QgdGhlaXIgdGhyZWUgbW9zdCBhbmQgdGhyZWUgbGVhc3QgaW1wb3J0YW50IGdvYWxzLiBOZXh0LCBwYXJ0aWNpcGFudHMgd2VyZSBhc2tlZCB0byBpZGVudGlmeSB0aGVpciBiZXN0IGZyaWVuZCBhbmQgdGhlaXIgYmVzdCBmcmllbmQncyBtb3N0IGRlc2NyaXB0aXZlIHN0cmVuZ3RoIGFuZCB3ZWFrbmVzcy4gQWZ0ZXJ3YXJkcywgcGFydGljaXBhbnRzIHdlcmUgYXNrZWQgdG8gd2hhdCBleHRlbnQgdGhlaXIgYmVzdCBmcmllbmQncyBtb3N0IGRlc2NyaXB0aXZlIHN0cmVuZ3RoIGFuZCB3ZWFrbmVzcyB3ZXJlIHJlbGV2YW50IHRvIGVhY2ggb2YgdGhlIHBhcnRpY2lwYW50cycgdGhyZWUgbW9zdCBhbmQgdGhyZWUgbGVhc3QgaW1wb3J0YW50IGdvYWxzLiBGaW5hbGx5LCBwYXJ0aWNpcGFudHMgd2VyZSBhc2tlZCB0byB3aGF0IGV4dGVudCB0aGV5IHdvdWxkIHRydXN0IHRoZWlyIGJlc3QgZnJpZW5kIGFjcm9zcyB0aGVpciB0aHJlZSBtb3N0IGFuZCB0aHJlZSBsZWFzdCBpbXBvcnRhbnQgZ29hbHMuIFRoZSBjcml0ZXJpb24gdmFyaWFibGUgb2YgdGhpcyBzdHVkeSwgb3IgdGhlIHRoaW5nIHdlIHdhbnQgdG8gcHJlZGljdCwgaXMgdGhlIHRydXN0IHBhcnRpY2lwYW50cyBwbGFjZWQgaW4gdGhlaXIgYmVzdCBmcmllbmQgYWNyb3NzIHRob3NlIHNpeCBnb2Fscy4NCjxici8+PGJyLz48YnIvPjxici8+DQoNCg0KDQoNCiMgRGF0YSBQcmUtcHJvY2Vzc2luZw0KVGhlIGZpcnN0IHN0ZXAgaW4gYW5hbHl6aW5nIGRhdGEgaW4gYGBgUmBgYCBpcyB0byBzZXQgeW91ciB3b3JraW5nIGVudmlyb25tZW50IGFuZCB0aGVuIGxvYWQgeW91ciBkYXRhIGFuZCByZXF1aXJlZCBwYWNrYWdlcy4gSSBoYXZlIGFscmVhZHkgZG9uZSB0aGF0IGluIHRoZSBiYWNrZ3JvdW5kLCBzbyBJIGVuY291cmFnZSB5b3UgdG8gZG93bmxvYWQgdGhlIGNvZGUgZm9yIHRoaXMgcGFnZSBpZiB5b3Ugd291bGQgbGlrZSB0byBzZWUgdGhhdCBzdGVwLiBJIHdpbGwgb25seSBzaG93IG9uZSBleGFtcGxlIG9mIGNvZGUgZm9yIGVhY2ggcHJlLXByb2Nlc3Npbmcgc3RlcCB0byBzYXZlIHByZWNpb3VzIGludGVybmV0IHNwYWNlLg0KDQpBZnRlciB5b3UndmUgc2V0IHVwIHlvdXIgZW52aW9ybm1lbnQgeW91IGNhbiBzdGFydCBwcmUtcHJvY2Vzc2luZyB5b3VyIGRhdGEgdG8gZ2V0IGl0IGludG8gdGhlIG5lY2Vzc2FyeSBmb3JtYXQgZm9yIGFuYWx5c2VzLiBCZWxvdywgSSBjcmVhdGUgYSBwYXJ0aWNpcGFudCBpZGVudGlmaWNhdGlvbiBudW1iZXIgKFBJTikgYW5kIHNldCBpdCBhcyBhIGZhY3Rvci4gVGhlbiBJIHJlbmFtZSB0aGUgdmFyaWFibGVzIHRoYXQgaWRlbnRpZnkgZXhhY3RseSAqaG93KiBpbXBvcnRhbnQsIG9uIGEgMSB0byAxMCBzY2FsZSwgcGFydGljaXBhbnRzIHZpZXdlZCB0aGVpciB0aHJlZSBtb3N0IGFuZCB0aHJlZSBsZWFzdCBpbXBvcnRhbnQgZ29hbHMuDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQojIENyZWF0aW5nIGEgUElODQpkYXRhMSRQSU48LXNlcShmcm9tPTEsIHRvPWxlbmd0aChkYXRhMSRQcm9ncmVzcykpDQojIFNldHRpbmcgdGhlIHZhcmlhYmxlIGFzIGEgZmFjdG9yIGZvciBhbmFseXNlcw0KZGF0YTEkUElOPC1hcy5mYWN0b3IoZGF0YTEkUElOKQ0KDQoNCiMjIENyZWF0aW5nIHZhcmlhYmxlcyBmb3IgdGhlIGNvbnRpbnVvdXMgbWVhc3VyZSBvZiBnb2FsIGltcG9ydGFuY2UgDQojIE1vc3QgSW1wb3J0YW50IEdvYWxzIA0KZGF0YTEkZzFJbXA8LShhcy5udW1lcmljKGRhdGExJFE1LjIpLTEpDQpgYGANCg0KYGBge3IsIHdhcm5pbmcgPSBGQUxTRSwgZWNobyA9IEZBTFNFfQ0KZGF0YTEkZzJJbXA8LShhcy5udW1lcmljKGRhdGExJFE2LjIpLTEpDQpkYXRhMSRnM0ltcDwtKGFzLm51bWVyaWMoZGF0YTEkUTcuMiktMSkNCiMgTGVhc3QgSW1wb3J0YW50IEdvYWxzDQpkYXRhMSRnNEltcDwtKGFzLm51bWVyaWMoZGF0YTEkUTguMiktMSkNCmRhdGExJGc1SW1wPC0oYXMubnVtZXJpYyhkYXRhMSRROS4yKS0xKQ0KZGF0YTEkZzZJbXA8LShhcy5udW1lcmljKGRhdGExJFExMC4yKS0xKQ0KDQpgYGANCg0KTmV4dCwgSSBoYXZlIHRvIGNyZWF0ZSB0aGUgdmFyaWFibGVzIHRoYXQgaW5kaWNhdGUgdG8gd2hhdCBleHRlbnQgcGFydGljaXBhbnRzJyBiZXN0IGZyaWVuZCdzIG1vc3QgZGVzY3JpcHRpdmUgc3RyZW5ndGggYW5kIHdlYWtuZXNzIHdlcmUgdG8gZWFjaCBvZiB0aGUgc2l4IGdvYWxzLiBIZXJlIGlzIHdoZXJlIHdlIGNvbWUgYWNyb3NzIG91ciBmaXJzdCBjb2RpbmcgY2hhbGxlbmdlLg0KDQpCZWNhdXNlIHRoaXMgc3VydmV5IHdhcyBpZGlvZ3JhcGhpY2FsbHktdGFpbG9yZWQsIGFuZCBwYXJ0aWNpcGFudHMgY291bGQgaGF2ZSBpZGVudGlmaWVkIGFueXdoZXJlIGZyb20gNiB0byAyNSBnb2FscywgdGhlc2UgZGF0YSBhcmUgd2hhdCdzIGtub3duIGFzICoqc3BhcnNlKiouIFNwYXJzZSBkYXRhIGhhcyBhIGxvdCBvZiBlbXB0eSBjZWxscywgYW5kIHRoaXMgd2FzIG9uZSBvZiB0aGUgc3BhcnNlc3QgZGF0YSBzZXRzIEkndmUgZXZlciB3b3JrZWQgd2l0aC4gSW4gdGhpcyBjYXNlLCB0aGVyZSB3YXMgYSBzaW5nbGUgdmFsdWUgZm9yIGV2ZXJ5IHBhcnRpY2lwYW50IHNjYXR0ZXJlZCBhY3Jvc3MgMzMgY29sdW1ucyEgSSBtZWFuLCB0YWtlIGEgbG9vayBhdCB0aGlzIGhvdCBtZXNzIQ0KDQpgYGB7cn0NCmhlYWQoZGF0YTFbLCAxMzExOjEzNDVdKQ0KYGBgDQoNCkhlcmUgaXMgdGhlIGNvZGUgSSB1c2VkIHRvIGNvbmRlbnNlIHRoYXQgc3BhcnNlIGRhdGEgaW50byBhIHNldCBvZiB2YXJpYWJsZXMgc28gdGhhdCBldmVyeSBwYXJ0aWNpcGFudHMnIHZhbHVlIHdhcyBpbmNsdWRlZCBpbiBhIHNpbmdsZSB2YXJpYWJsZS4NCg0KYGBge3IsIHdhcm5pbmcgPSBGQUxTRX0NCiMjIyBDcmVhdGluZyBHb2FsIFJlbGV2YW5jZSBWYXJpYWJsZXMgDQojIyBNb3N0IEltcG9ydGFudCBHb2FscyAjIyMjIyMjIyMjDQojIEdvYWwgMSBTdHJlbmd0aA0KZGF0YTEkR29hbDFTdHJSZWw8LShhcHBseShkYXRhMVssIDEzMTE6MTM0NV0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpLTENCmBgYA0KDQpgYGB7ciwgd2FybmluZyA9IEZBTFNFLCBlY2hvID0gRkFMU0V9DQojIEdvYWwgMSBXZWFrbmVzcw0KZGF0YTEkR29hbDFXZWFrUmVsPC0oYXBwbHkoZGF0YTFbLCAxMzQ2OjEzODBdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKS0xDQojIEdvYWwgMiBTdHJlbmd0aA0KZGF0YTEkR29hbDJTdHJSZWw8LShhcHBseShkYXRhMVssIDEzODE6MTQxNV0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpLTENCiMgR29hbCAyIFdlYWtuZXNzDQpkYXRhMSRHb2FsMldlYWtSZWw8LShhcHBseShkYXRhMVssIDE0MTY6MTQ1MF0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpLTENCiMgR29hbCAzIFN0cmVuZ3RoDQpkYXRhMSRHb2FsM1N0clJlbDwtKGFwcGx5KGRhdGExWywgMTQ1MToxNDg1XSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSktMQ0KIyBHb2FsIDMgV2Vha25lc3MNCmRhdGExJEdvYWwzV2Vha1JlbDwtKGFwcGx5KGRhdGExWywgMTQ4NjoxNTIwXSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSktMQ0KIyMgTGVhc3QgSW1wb3J0YW50IEdvYWxzDQojIEdvYWwgNCBTdHJlbmd0aA0KZGF0YTEkR29hbDRTdHJSZWw8LShhcHBseShkYXRhMVssIDE1MjE6MTU1NV0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpLTENCiMgR29hbCA0IFdlYWtuZXNzDQpkYXRhMSRHb2FsNFdlYWtSZWw8LShhcHBseShkYXRhMVssIDE1NTY6MTU5MF0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpLTENCiMgR29hbCA1IFN0cmVuZ3RoDQpkYXRhMSRHb2FsNVN0clJlbDwtKGFwcGx5KGRhdGExWywgMTU5MToxNjI1XSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSktMQ0KIyBHb2FsIDUgV2Vha25lc3MNCmRhdGExJEdvYWw1V2Vha1JlbDwtKGFwcGx5KGRhdGExWywgMTYyNjoxNjYwXSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSktMQ0KIyBHb2FsIDYgU3RyZW5ndGgNCmRhdGExJEdvYWw2U3RyUmVsPC0oYXBwbHkoZGF0YTFbLCAxNjYxOjE2OTVdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKS0xDQojIEdvYWwgNiBXZWFrbmVzcw0KZGF0YTEkR29hbDZXZWFrUmVsPC0oYXBwbHkoZGF0YTFbLCAxNjk2OjE3MzBdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKS0xDQpgYGANCg0KTGV0J3Mgc2VlIGlmIHRoYXQgd29ya2VkLg0KDQpgYGB7cn0NCmhlYWQoZGF0YTEkR29hbDFTdHJSZWw6ZGF0YTEkR29hbDZTdHJSZWwpDQpgYGANCg0KR3JlYXQhIE5vdyB3ZSBoYXZlIGNvbmRlbnNlZCBvdXIgZmlyc3Qgc2V0IG9mIHByZWRpY3RvcnMsIGFuZCBpdCdzIHRpbWUgdG8gbW92ZSBvbnRvIHRoZSBuZXh0IHNldCBvZiB2YXJpYWJsZXMuDQoNClRoZSB2YXJpYWJsZXMgdGhhdCBjb250YWluZWQgcGFydGljaXBhbnRzJyB0cnVzdCBpbiB0aGVpciBiZXN0IGZyaWVuZCBhY3Jvc3MgZWFjaCBnb2FsIHdhcyBzaW1pbGFybHkgc3BhcnNlLCBzbyBJIHNpbXBseSBhcHBsaWVkIHRoZSBzYW1lIGNvZGUgdG8gZml4IHRoYXQgaGVyZS4gSG93ZXZlciwgdGhlIG1lYXN1cmVzIGZvciBnb2FsLXNwZWNpZmljIHRydXN0IHdlcmUgYSBiaXQgbW9yZSBjb21wbGljYXRlZCwgc28gdGhleSByZXF1aXJlIG1vcmUgY29kZS4gU3BlY2lmaWNhbGx5LCBwYXJ0aWNpcGFudHMgd2VyZSBmaXJzdCBhc2tlZCBpZiB0aGV5IHRydXN0ZWQgdGhlaXIgYmVzdCBmcmllbmQgb3Igbm90IGZvciBlYWNoIGdvYWwsIGFuZCB0aGVuIHRoZXkgd2VyZSBhc2tlZCB0byB3aGF0IGV4dGVudCB0aGV5IHRydXN0ZWQgb3IgZGlzdHJ1c3RlZCB0aGVpciBiZXN0IGZyaWVuZCwgZGVwZW5kaW5nIG9uIHdoZXRoZXIgdGhleSBmaXJzdCBzZWxjdGVkIHRydXN0IG9yIGRpc3RydXN0LiBCZWNhdXNlIHdlIHdhcyBhIGNvbnRpbnVvdXMgbWVhc3VyZSBmb3Igb3VyIGFuYWx5c2VzLCB3ZSBuZWVkIHRvIHNvbWVob3cgY29tYmluZSB0aG9zZSBleHRlbnQgdmFyaWFibGVzIHdpdGggdGhlIGRpY2hvdG9tb3VzIG1lYXN1cmUuIEJlbG93IGlzIHRoZSBjb2RlIGZvciBob3cgSSBhY2NvbXBsaXNoZWQgdGhhdC4gDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQojIyMgQ3JlYXRpbmcgR29hbC1CYXNlZCBUcnVzdCBEVnMgIyMjDQojIyBUcnVzdCBmb3IgUHJvamVjdCAxIA0KIyBUcnVzdA0KZGF0YTEkR29hbDFUcnVzdERpPC0oYXBwbHkoZGF0YTFbLCAxNzMxOjE3NjVdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEcxVHJ1c3RFeHQ8LWFzLm51bWVyaWMoZGF0YTEkUTI2LjIpDQojIEV4dGVudCBTcyBkaXN0cnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzFEaXN0cnVzdEV4dDwtYXMubnVtZXJpYygtZGF0YTEkUTI2LjMpDQojIExlYW4gVG93YXJkIFRydXN0IHZzIERpc3RydXN0DQpkYXRhMSRHMVRydXN0TGVhbjwtYXMubnVtZXJpYyhkYXRhMSRRMjYuNCkNCiMgQ3JlYXRpbmcgYmlwb2xhciBtZWFzdXJlIG9mIFRydXN0LURpc3RydXN0DQpkYXRhMSRHb2FsMVRydXN0QlA8LWlmZWxzZShkYXRhMSRHb2FsMVRydXN0RGk9PTEsZGF0YTEkRzFUcnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHb2FsMVRydXN0RGk9PTIsZGF0YTEkRzFEaXN0cnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHMVRydXN0TGVhbj09MSwxLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEcxVHJ1c3RMZWFuPT0yLC0xLE5BKSkpKQ0KDQojIFJlbHkNCmRhdGExJEdvYWwxUmVseURpPC0oYXBwbHkoZGF0YTFbLCAxNzY5OjE4MDNdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEcxUmVseUV4dDwtYXMubnVtZXJpYyhkYXRhMSRRMjYuNikNCiMgRXh0ZW50IFNzIGRpc3RydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHMVVucmVseURpRXh0PC1hcy5udW1lcmljKC1kYXRhMSRRMjYuNykNCiMgTGVhbiBUb3dhcmQgVHJ1c3QgdnMgRGlzdHJ1c3QNCmRhdGExJEcxUmVseUxlYW48LWFzLm51bWVyaWMoZGF0YTEkUTI2LjgpDQojIENyZWF0aW5nIGJpcG9sYXIgbWVhc3VyZSBvZiBUcnVzdC1EaXN0cnVzdA0KZGF0YTEkR29hbDFSZWx5QlA8LWlmZWxzZShkYXRhMSRHb2FsMVJlbHlEaT09MSxkYXRhMSRHMVJlbHlFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkR29hbDFSZWx5RGk9PTIsZGF0YTEkRzFVbnJlbHlEaUV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHMVJlbHlMZWFuPT0xLDEsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzFSZWx5TGVhbj09MiwtMSxOQSkpKSkNCmBgYA0KDQpgYGB7ciwgd2FybmluZyA9IEZBTFNFLCBlY2hvID0gRkFMU0V9DQojIyBUcnVzdCBmb3IgUHJvamVjdCAyIA0KIyBUcnVzdA0KZGF0YTEkR29hbDJUcnVzdERpPC0oYXBwbHkoZGF0YTFbLCAxODA3OjE4NDFdLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEcyVHJ1c3RFeHQ8LWFzLm51bWVyaWMoZGF0YTEkUTI3LjIpDQojIEV4dGVudCBTcyBkaXN0cnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzJEaXN0cnVzdEV4dDwtYXMubnVtZXJpYygtZGF0YTEkUTI3LjMpDQojIExlYW4gVG93YXJkIFRydXN0IHZzIERpc3RydXN0DQpkYXRhMSRHMlRydXN0TGVhbjwtYXMubnVtZXJpYyhkYXRhMSRRMjcuNCkNCiMgQ3JlYXRpbmcgYmlwb2xhciBtZWFzdXJlIG9mIFRydXN0LURpc3RydXN0DQpkYXRhMSRHb2FsMlRydXN0QlA8LWlmZWxzZShkYXRhMSRHb2FsMlRydXN0RGk9PTEsZGF0YTEkRzJUcnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHb2FsMlRydXN0RGk9PTIsZGF0YTEkRzJEaXN0cnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHMlRydXN0TGVhbj09MSwxLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEcyVHJ1c3RMZWFuPT0yLC0xLE5BKSkpKQ0KDQojIFJlbHkNCmRhdGExJEdvYWwyUmVseURpPC0oYXBwbHkoZGF0YTFbLCAxODQ1OjE4NzldLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEcyUmVseUV4dDwtYXMubnVtZXJpYyhkYXRhMSRRMjcuNikNCiMgRXh0ZW50IFNzIGRpc3RydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHMlVucmVseURpRXh0PC1hcy5udW1lcmljKC1kYXRhMSRRMjcuNykNCiMgTGVhbiBUb3dhcmQgVHJ1c3QgdnMgRGlzdHJ1c3QNCmRhdGExJEcyUmVseUxlYW48LWFzLm51bWVyaWMoZGF0YTEkUTI3LjgpDQojIENyZWF0aW5nIGJpcG9sYXIgbWVhc3VyZSBvZiBUcnVzdC1EaXN0cnVzdA0KZGF0YTEkR29hbDJSZWx5QlA8LWlmZWxzZShkYXRhMSRHb2FsMlJlbHlEaT09MSxkYXRhMSRHMlJlbHlFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHb2FsMlJlbHlEaT09MixkYXRhMSRHMlVucmVseURpRXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzJSZWx5TGVhbj09MSwxLA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzJSZWx5TGVhbj09MiwtMSxOQSkpKSkNCg0KIyMgVHJ1c3QgZm9yIFByb2plY3QgMyANCiMgVHJ1c3QNCmRhdGExJEdvYWwzVHJ1c3REaTwtKGFwcGx5KGRhdGExWywgMTg4MzoxOTE3XSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSkNCiMgRXh0ZW50IFNzIFRydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHM1RydXN0RXh0PC1hcy5udW1lcmljKGRhdGExJFEyOC4yKQ0KIyBFeHRlbnQgU3MgZGlzdHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEczRGlzdHJ1c3RFeHQ8LWFzLm51bWVyaWMoLWRhdGExJFEyOC4zKQ0KIyBMZWFuIFRvd2FyZCBUcnVzdCB2cyBEaXN0cnVzdA0KZGF0YTEkRzNUcnVzdExlYW48LWFzLm51bWVyaWMoZGF0YTEkUTI4LjQpDQojIENyZWF0aW5nIGJpcG9sYXIgbWVhc3VyZSBvZiBUcnVzdC1EaXN0cnVzdA0KZGF0YTEkR29hbDNUcnVzdEJQPC1pZmVsc2UoZGF0YTEkR29hbDNUcnVzdERpPT0xLGRhdGExJEczVHJ1c3RFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkR29hbDNUcnVzdERpPT0yLGRhdGExJEczRGlzdHJ1c3RFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzNUcnVzdExlYW49PTEsMSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHM1RydXN0TGVhbj09MiwtMSxOQSkpKSkNCg0KIyBSZWx5DQpkYXRhMSRHb2FsM1JlbHlEaTwtKGFwcGx5KGRhdGExWywgMTkyMToxOTU1XSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSkNCiMgRXh0ZW50IFNzIFRydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHM1JlbHlFeHQ8LWFzLm51bWVyaWMoZGF0YTEkUTI4LjYpDQojIEV4dGVudCBTcyBkaXN0cnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzNVbnJlbHlEaUV4dDwtYXMubnVtZXJpYygtZGF0YTEkUTI4LjcpDQojIExlYW4gVG93YXJkIFRydXN0IHZzIERpc3RydXN0DQpkYXRhMSRHM1JlbHlMZWFuPC1hcy5udW1lcmljKGRhdGExJFEyOC44KQ0KIyBDcmVhdGluZyBiaXBvbGFyIG1lYXN1cmUgb2YgVHJ1c3QtRGlzdHJ1c3QNCmRhdGExJEdvYWwzUmVseUJQPC1pZmVsc2UoZGF0YTEkR29hbDNSZWx5RGk9PTEsZGF0YTEkRzNSZWx5RXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkR29hbDNSZWx5RGk9PTIsZGF0YTEkRzNVbnJlbHlEaUV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEczUmVseUxlYW49PTEsMSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEczUmVseUxlYW49PTIsLTEsTkEpKSkpDQoNCiMjIFRydXN0IGZvciBQcm9qZWN0IDQgDQojIFRydXN0DQpkYXRhMSRHb2FsNFRydXN0RGk8LShhcHBseShkYXRhMVssIDE5NTk6MTk5M10sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpDQojIEV4dGVudCBTcyBUcnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzRUcnVzdEV4dDwtYXMubnVtZXJpYyhkYXRhMSRRMjkuMikNCiMgRXh0ZW50IFNzIGRpc3RydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHNERpc3RydXN0RXh0PC1hcy5udW1lcmljKC1kYXRhMSRRMjkuMykNCiMgTGVhbiBUb3dhcmQgVHJ1c3QgdnMgRGlzdHJ1c3QNCmRhdGExJEc0VHJ1c3RMZWFuPC1hcy5udW1lcmljKGRhdGExJFEyOS40KQ0KIyBDcmVhdGluZyBiaXBvbGFyIG1lYXN1cmUgb2YgVHJ1c3QtRGlzdHJ1c3QNCmRhdGExJEdvYWw0VHJ1c3RCUDwtaWZlbHNlKGRhdGExJEdvYWw0VHJ1c3REaT09MSxkYXRhMSRHNFRydXN0RXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEdvYWw0VHJ1c3REaT09MixkYXRhMSRHNERpc3RydXN0RXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEc0VHJ1c3RMZWFuPT0xLDEsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzRUcnVzdExlYW49PTIsLTEsTkEpKSkpDQoNCiMgUmVseQ0KZGF0YTEkR29hbDRSZWx5RGk8LShhcHBseShkYXRhMVssIDE5OTc6MjAzMV0sIDEsIGZ1bmN0aW9uKHgpIHhbIWlzLm5hKHgpXVsxXSkpDQojIEV4dGVudCBTcyBUcnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzRSZWx5RXh0PC1hcy5udW1lcmljKGRhdGExJFEyOS42KQ0KIyBFeHRlbnQgU3MgZGlzdHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEc0VW5yZWx5RGlFeHQ8LWFzLm51bWVyaWMoLWRhdGExJFEyOS43KQ0KIyBMZWFuIFRvd2FyZCBUcnVzdCB2cyBEaXN0cnVzdA0KZGF0YTEkRzRSZWx5TGVhbjwtYXMubnVtZXJpYyhkYXRhMSRRMjkuOCkNCiMgQ3JlYXRpbmcgYmlwb2xhciBtZWFzdXJlIG9mIFRydXN0LURpc3RydXN0DQpkYXRhMSRHb2FsNFJlbHlCUDwtaWZlbHNlKGRhdGExJEdvYWw0UmVseURpPT0xLGRhdGExJEc0UmVseUV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEdvYWw0UmVseURpPT0yLGRhdGExJEc0VW5yZWx5RGlFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHNFJlbHlMZWFuPT0xLDEsDQogICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHNFJlbHlMZWFuPT0yLC0xLE5BKSkpKQ0KDQojIyBUcnVzdCBmb3IgUHJvamVjdCA1IA0KIyBUcnVzdA0KZGF0YTEkR29hbDVUcnVzdERpPC0oYXBwbHkoZGF0YTFbLCAyMDM1OjIwNjldLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEc1VHJ1c3RFeHQ8LWFzLm51bWVyaWMoZGF0YTEkUTMwLjIpDQojIEV4dGVudCBTcyBkaXN0cnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzVEaXN0cnVzdEV4dDwtYXMubnVtZXJpYygtZGF0YTEkUTMwLjMpDQojIExlYW4gVG93YXJkIFRydXN0IHZzIERpc3RydXN0DQpkYXRhMSRHNVRydXN0TGVhbjwtYXMubnVtZXJpYyhkYXRhMSRRMzAuNCkNCiMgQ3JlYXRpbmcgYmlwb2xhciBtZWFzdXJlIG9mIFRydXN0LURpc3RydXN0DQpkYXRhMSRHb2FsNVRydXN0QlA8LWlmZWxzZShkYXRhMSRHb2FsNVRydXN0RGk9PTEsZGF0YTEkRzVUcnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHb2FsNVRydXN0RGk9PTIsZGF0YTEkRzVEaXN0cnVzdEV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHNVRydXN0TGVhbj09MSwxLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEc1VHJ1c3RMZWFuPT0yLC0xLE5BKSkpKQ0KDQojIFJlbHkNCmRhdGExJEdvYWw1UmVseURpPC0oYXBwbHkoZGF0YTFbLCAyMDczOjIxMDddLCAxLCBmdW5jdGlvbih4KSB4WyFpcy5uYSh4KV1bMV0pKQ0KIyBFeHRlbnQgU3MgVHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEc1UmVseUV4dDwtYXMubnVtZXJpYyhkYXRhMSRRMzAuNikNCiMgRXh0ZW50IFNzIGRpc3RydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHNVVucmVseURpRXh0PC1hcy5udW1lcmljKC1kYXRhMSRRMzAuNykNCiMgTGVhbiBUb3dhcmQgVHJ1c3QgdnMgRGlzdHJ1c3QNCmRhdGExJEc1UmVseUxlYW48LWFzLm51bWVyaWMoZGF0YTEkUTMwLjgpDQojIENyZWF0aW5nIGJpcG9sYXIgbWVhc3VyZSBvZiBUcnVzdC1EaXN0cnVzdA0KZGF0YTEkR29hbDVSZWx5QlA8LWlmZWxzZShkYXRhMSRHb2FsNVJlbHlEaT09MSxkYXRhMSRHNVJlbHlFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHb2FsNVJlbHlEaT09MixkYXRhMSRHNVVucmVseURpRXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzVSZWx5TGVhbj09MSwxLA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzVSZWx5TGVhbj09MiwtMSxOQSkpKSkNCg0KIyMgVHJ1c3QgZm9yIFByb2plY3QgNiANCiMgVHJ1c3QNCmRhdGExJEdvYWw2VHJ1c3REaTwtKGFwcGx5KGRhdGExWywgMjExMToyMTQ1XSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSkNCiMgRXh0ZW50IFNzIFRydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHNlRydXN0RXh0PC1hcy5udW1lcmljKGRhdGExJFEzMS4yKQ0KIyBFeHRlbnQgU3MgZGlzdHJ1c3RzIEJlc3QgRnJpZW5kIGZvciBQcm9qZWN0IDENCmRhdGExJEc2RGlzdHJ1c3RFeHQ8LWFzLm51bWVyaWMoLWRhdGExJFEzMS4zKQ0KIyBMZWFuIFRvd2FyZCBUcnVzdCB2cyBEaXN0cnVzdA0KZGF0YTEkRzZUcnVzdExlYW48LWFzLm51bWVyaWMoZGF0YTEkUTMxLjQpDQojIENyZWF0aW5nIGJpcG9sYXIgbWVhc3VyZSBvZiBUcnVzdC1EaXN0cnVzdA0KZGF0YTEkR29hbDZUcnVzdEJQPC1pZmVsc2UoZGF0YTEkR29hbDZUcnVzdERpPT0xLGRhdGExJEc2VHJ1c3RFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkR29hbDZUcnVzdERpPT0yLGRhdGExJEc2RGlzdHJ1c3RFeHQsDQogICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkRzZUcnVzdExlYW49PTEsMSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGlmZWxzZShkYXRhMSRHNlRydXN0TGVhbj09MiwtMSxOQSkpKSkNCg0KIyBSZWx5DQpkYXRhMSRHb2FsNlJlbHlEaTwtKGFwcGx5KGRhdGExWywgMjE0OToyMTgzXSwgMSwgZnVuY3Rpb24oeCkgeFshaXMubmEoeCldWzFdKSkNCiMgRXh0ZW50IFNzIFRydXN0cyBCZXN0IEZyaWVuZCBmb3IgUHJvamVjdCAxDQpkYXRhMSRHNlJlbHlFeHQ8LWFzLm51bWVyaWMoZGF0YTEkUTMxLjYpDQojIEV4dGVudCBTcyBkaXN0cnVzdHMgQmVzdCBGcmllbmQgZm9yIFByb2plY3QgMQ0KZGF0YTEkRzZVbnJlbHlEaUV4dDwtYXMubnVtZXJpYygtZGF0YTEkUTMxLjcpDQojIExlYW4gVG93YXJkIFRydXN0IHZzIERpc3RydXN0DQpkYXRhMSRHNlJlbHlMZWFuPC1hcy5udW1lcmljKGRhdGExJFEzMS44KQ0KIyBDcmVhdGluZyBiaXBvbGFyIG1lYXN1cmUgb2YgVHJ1c3QtRGlzdHJ1c3QNCmRhdGExJEdvYWw2UmVseUJQPC1pZmVsc2UoZGF0YTEkR29hbDZSZWx5RGk9PTEsZGF0YTEkRzZSZWx5RXh0LA0KICAgICAgICAgICAgICAgICAgICAgICAgICBpZmVsc2UoZGF0YTEkR29hbDZSZWx5RGk9PTIsZGF0YTEkRzZVbnJlbHlEaUV4dCwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEc2UmVseUxlYW49PTEsMSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgaWZlbHNlKGRhdGExJEc2UmVseUxlYW49PTIsLTEsTkEpKSkpDQpgYGANCg0KV2hldyEhIFRoYXQncyBhIGxvdCEgQnV0IHdlJ3JlIGFsbW9zdCBkb25lLiBXZSBoYXZlIGNyZWF0ZWQgb3VyIFBJTiwgdGhlIGNvbnRpbnVvdXMgbWVhc3VyZSBvZiBnb2FsIG1wb3J0YW5jZSAoZm9yIGEgbWFuaXB1bGF0aW9uIGNoZWNrKSwgdGhlIHJlbGV2YW5jZSBvZiB0aGUgYmVzdCBmcmllbmQncyBtb3N0IGRlc2NyaXB0aXZlIHN0cmVuZ3RoIGFuZCB3ZWFrbmVzcyB0byBlYWNoIGdvYWwsIGFuZCB0aGUgbWVhc3VyZSBvZiBnb2FsLXNwZWNpZmljIHRydXN0LiBBbGwgdGhhdCBpcyBsZWZ0IGlzIHRvIGNyZWF0ZSBhIHN1YnNldCBvZiB0aGUgZGF0YSB3aXRoIG9ubHkgdGhlIHZhcmlhYmxlcyB0aGF0IHdlIG5lZWQgYW5kIHRvIHB1dCBpdCBpbnRvIHRoZSBwcm9wZXIgZm9ybWF0Lg0KDQpIZXJlLCBJIHN1YnNldCB0aGUgZGF0YSBhbmQgY3JlYXRlIHRoZSBkYXRhZnJhbW1lIHRoYXQgSSdsbCB1c2UgZm9yIHBsb3R0aW5nIGFuZCBteSBhbmFseXNlcw0KDQpgYGB7ciwgd2FybmluZyA9IEZBTFNFfQ0KZGF0YTI8LXN1YnNldChkYXRhMSxzZWxlY3Q9YyhQSU46R29hbDFUcnVzdERpLEdvYWwxVHJ1c3RCUCxHb2FsMVJlbHlEaSxHb2FsMVJlbHlCUCxHb2FsMlRydXN0RGksDQogICAgICAgICAgICAgICAgICAgICAgICAgICAgIEdvYWwyVHJ1c3RCUCxHb2FsMlJlbHlEaSxHb2FsMlJlbHlCUCxHb2FsM1RydXN0RGksR29hbDNUcnVzdEJQLEdvYWwzUmVseURpLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICBHb2FsM1JlbHlCUCxHb2FsNFRydXN0RGksR29hbDRUcnVzdEJQLEdvYWw0UmVseURpLEdvYWw0UmVseUJQLEdvYWw1VHJ1c3REaSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgR29hbDVUcnVzdEJQLEdvYWw1UmVseURpLEdvYWw1UmVseUJQLEdvYWw2VHJ1c3REaSxHb2FsNlRydXN0QlAsR29hbDZSZWx5RGksDQogICAgICAgICAgICAgICAgICAgICAgICAgICAgIEdvYWw2UmVseUJQKSkgDQpgYGANCg0KTGV0J3MgY2hlY2sgaXQgdG8gbWFrZSBzdXJlIGV2ZXJ5dGhpbmcgd29ya2VkIHByb3Blcmx5DQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQpzdHIoZGF0YTIpDQpgYGANCg0KUGVyZmVjdCEgTm93LCBsZXQncyBhcnJhbmdlIHRoZSB2YXJpYWJsZXMgZm9yIGVhc2llciBtYW5pcHVsYXRpb24gYW5kIHNldCBiZXR0ZXIgbmFtZXMuIEluIG9yZGVyIHRvIGRvIHRoaXMsIHdlJ2xsIG5lZWQgdG8gY29udmVydCBvdXIgZGF0YSBmcm9tICoqd2lkZSBmb3JtYXQqKiB0byAqKmxvbmcgZm9ybWF0KiouDQoNCk1vc3QgcGVvcGxlIGFyZSBwcm9iYWJseSBtb3JlIGZhbWlsaWFyIHdpdGggKip3aWRlIGZvcm1hdCoqLiBJbiAqKndpZGUgZm9ybWF0KiosIGV2ZXJ5IGNvbHVtbiBpcyBhIHZhcmlhYmxlLCBhbmQgZXZlcnkgcm93IGlzIGEgY2FzZSBvciBpbnN0YW5jZSBvZiB0aGUgdmFyaWFibGUgInBhcnRpY2lwYW50LiIgSW4gb3RoZXIgd29yZHMsIGVhY2ggY2FzZSByZXByZXNlbnRzIGEgc2luZ2xlIHBhcnRpY2lwYW50LiBJbiAqKmxvbmcgZm9ybWF0KiosIHdlIHN0cmV0Y2ggb3V0IG91ciBkYXRhIHNvIHRoYXQgZWFjaCBwYXJ0aWNpcGFudCBvY2N1cGllcyBtdWx0aW1wbGUgcm93cy4gSW4gdGhlIGVuZCBvZiB0aGlzIHRyYW5zZm9ybWF0aW9uLCBlYWNoIHJvdyB3aWxsIGJlIGFuIGluc3RhbmNlIG9yIGNhc2Ugb2YgdGhlIHZhcmlhYmxlICJnb2FsIiBzbyB0aGF0IGV2ZXJ5IHBhcnRpY2lwYW50IHdpbGwgb2NjdXB5ICoqNioqIHJvd3MsIG9uZSBmb3IgZWFjaCBvZiB0aGVpciB0aHJlZSBtb3N0IGFuZCB0aHJlZSBsZWFzdCBpbXBvcnRhbnQgZ29hbHMuDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQojIyMgQXJyYW5naW5nIGNvbHVtbnMgZm9yIGVhc2llciBtYW5pcHVsYXRpb24gDQojIyBHb2FsIEltcG9ydGFuY2UgDQojIFNlbGVjdCB2YXJzDQppbXBEYXRhPC1kYXRhMiAlPiUgZHBseXI6OnNlbGVjdCh0aWR5c2VsZWN0Ojp2YXJzX3NlbGVjdChuYW1lcyhkYXRhMiksIGRwbHlyOjptYXRjaGVzKCdJbXAnKSkpDQojIEFkZCBQSU4NCmltcERhdGEkUElOPC1kYXRhMiRQSU4NCiMgV2lkZSB0byBMb25nDQppbXBMb25nPC1pbXBEYXRhICU+JSBnYXRoZXIoR29hbCxJbXBvcnRhbmNlLGcxSW1wOmc2SW1wKQ0KIyBSZW5hbWUgZmFjdG9yIGxldmVscw0KaW1wTG9uZyRHb2FsPC1tYXB2YWx1ZXMoaW1wTG9uZyRHb2FsLCBmcm9tID0gYygiZzFJbXAiLCJnMkltcCIsImczSW1wIiwiZzRJbXAiLCJnNUltcCIsImc2SW1wIiksDQogICAgICAgICAgICAgICAgICAgICAgICB0byA9IGMoIkdvYWwxIiwiR29hbDIiLCJHb2FsMyIsIkdvYWw0IiwiR29hbDUiLCJHb2FsNiIpKQ0KDQojIyBSZWxldmFuY2Ugb2Ygc3RyZW5ndGggdG8gZWFjaCBwcm9qZWN0IA0KIyBTZWxlY3QgdmFycw0Kc3RyZW5ndGhEYXRhPC1kYXRhMiAlPiUgZHBseXI6OnNlbGVjdCh0aWR5c2VsZWN0Ojp2YXJzX3NlbGVjdChuYW1lcyhkYXRhMiksIG1hdGNoZXMoJ1N0clJlbCcpKSkNCiMgQWRkIFBJTg0Kc3RyZW5ndGhEYXRhJFBJTjwtZGF0YTIkUElODQojIFdpZGUgdG8gTG9uZw0Kc3JlbExvbmc8LXN0cmVuZ3RoRGF0YSAlPiUgZ2F0aGVyKEdvYWwsU3RSZWwsR29hbDFTdHJSZWw6R29hbDZTdHJSZWwpDQojIFJlbmFtZSBmYWN0b3IgbGV2ZWxzDQpzcmVsTG9uZyRHb2FsPC1tYXB2YWx1ZXMoc3JlbExvbmckR29hbCwgZnJvbSA9IGMoIkdvYWwxU3RyUmVsIiwiR29hbDJTdHJSZWwiLCJHb2FsM1N0clJlbCIsIkdvYWw0U3RyUmVsIiwiR29hbDVTdHJSZWwiLCJHb2FsNlN0clJlbCIpLA0KICAgICAgICAgICAgICAgICAgICAgICAgIHRvID0gYygiR29hbDEiLCJHb2FsMiIsIkdvYWwzIiwiR29hbDQiLCJHb2FsNSIsIkdvYWw2IikpDQoNCiMjIFJlbGV2YW5jZSBvZiB3ZWFrbmVzcyB0byBlYWNoIHByb2plY3QgDQojIFNlbGVjdCB2YXJzDQp3ZWFrRGF0YTwtZGF0YTIgJT4lIGRwbHlyOjpzZWxlY3QodGlkeXNlbGVjdDo6dmFyc19zZWxlY3QobmFtZXMoZGF0YTIpLCBtYXRjaGVzKCdXZWFrUmVsJykpKQ0KIyBBZGQgUElODQp3ZWFrRGF0YSRQSU48LWRhdGEyJFBJTg0KIyBXaWRlIHRvIExvbmcNCndyZWxMb25nPC13ZWFrRGF0YSAlPiUgZ2F0aGVyKEdvYWwsV2Vha1JlbCxHb2FsMVdlYWtSZWw6R29hbDZXZWFrUmVsKQ0KIyBSZW5hbWUgZmFjdG9yIGxldmVscw0Kd3JlbExvbmckR29hbDwtbWFwdmFsdWVzKHdyZWxMb25nJEdvYWwsIGZyb20gPSBjKCJHb2FsMVdlYWtSZWwiLCJHb2FsMldlYWtSZWwiLCJHb2FsM1dlYWtSZWwiLCJHb2FsNFdlYWtSZWwiLCJHb2FsNVdlYWtSZWwiLCJHb2FsNldlYWtSZWwiKSwNCiAgICAgICAgICAgICAgICAgICAgICAgICB0byA9IGMoIkdvYWwxIiwiR29hbDIiLCJHb2FsMyIsIkdvYWw0IiwiR29hbDUiLCJHb2FsNiIpKQ0KDQojIyBUcnVzdCBiZXN0IGZyaWVuZCANCiMgU2VsZWN0IHZhcnMNCnRydXN0RGF0YTwtZGF0YTIgJT4lIGRwbHlyOjpzZWxlY3QodGlkeXNlbGVjdDo6dmFyc19zZWxlY3QobmFtZXMoZGF0YTIpLCBtYXRjaGVzKCdUcnVzdEJQJykpKQ0KIyBBZGQgUElODQp0cnVzdERhdGEkUElOPC1kYXRhMiRQSU4NCiMgV2lkZSB0byBMb25nDQp0TG9uZzwtdHJ1c3REYXRhICU+JSBnYXRoZXIoR29hbCxUcnVzdCxHb2FsMVRydXN0QlA6R29hbDZUcnVzdEJQKQ0KIyBSZW5hbWUgZmFjdG9yIGxldmVscw0KdExvbmckR29hbDwtbWFwdmFsdWVzKHRMb25nJEdvYWwsIGZyb20gPSBjKCJHb2FsMVRydXN0QlAiLCJHb2FsMlRydXN0QlAiLCJHb2FsM1RydXN0QlAiLCJHb2FsNFRydXN0QlAiLCJHb2FsNVRydXN0QlAiLCJHb2FsNlRydXN0QlAiKSwNCiAgICAgICAgICAgICAgICAgICAgICB0byA9IGMoIkdvYWwxIiwiR29hbDIiLCJHb2FsMyIsIkdvYWw0IiwiR29hbDUiLCJHb2FsNiIpKQ0KDQojIyBSZWx5IG9uIGJlc3QgZnJpZW5kIA0KIyBTZWxlY3QgdmFycw0KcmVseURhdGE8LWRhdGEyICU+JSBkcGx5cjo6c2VsZWN0KHRpZHlzZWxlY3Q6OnZhcnNfc2VsZWN0KG5hbWVzKGRhdGEyKSwgbWF0Y2hlcygnUmVseUJQJykpKQ0KIyBBZGQgUElODQpyZWx5RGF0YSRQSU48LWRhdGEyJFBJTg0KIyBXaWRlIHRvIExvbmcNCnJMb25nPC1yZWx5RGF0YSAlPiUgZ2F0aGVyKEdvYWwsUmVseSxHb2FsMVJlbHlCUDpHb2FsNlJlbHlCUCkNCiMgUmVuYW1lIGZhY3RvciBsZXZlbHMNCnJMb25nJEdvYWw8LW1hcHZhbHVlcyhyTG9uZyRHb2FsLCBmcm9tID0gYygiR29hbDFSZWx5QlAiLCJHb2FsMlJlbHlCUCIsIkdvYWwzUmVseUJQIiwiR29hbDRSZWx5QlAiLCJHb2FsNVJlbHlCUCIsIkdvYWw2UmVseUJQIiksDQogICAgICAgICAgICAgICAgICAgICAgdG8gPSBjKCJHb2FsMSIsIkdvYWwyIiwiR29hbDMiLCJHb2FsNCIsIkdvYWw1IiwiR29hbDYiKSkNCmBgYA0KDQpOb3cgdGhhdCB3ZSd2ZSBjcmVhdGVkIHNldmVyYWwgc21hbGxlciBkYXRhZnJhbWVzIGluICoqbG9uZyBmb3JtYXQqKiwgbGV0J3MgbWVyZ2UgdGhlbSB0b2dldGhlciB0byBjcmVhdGUgYSBkYXRhZnJhbWUgdGhhdCdzIGluICoqbG9uZyBmb3JtYXQqKiBhbmQgaGFzIGFsbCBvZiBvdXIgdmFyaWFibGVzLiBXaGlsZSB3ZSdyZSBkb2luZyB0aGlzLCB3ZSB3aWxsIGNyZWF0ZSBhIGNhdGVnb3JpY2FsIHZhcmlhYmxlIHRoYXQgaW5kaWNhdGVzIHdoZXRoZXIgYSBnb2FsIGlzIG9uZSBvZiB0aGUgdGhyZWUgbW9zdCBvciB0aHJlZSBsZWFzdCBpbXBvcnRhbnQgZ29hbHMuIA0KDQpgYGB7ciwgd2FybmluZyA9IEZBTFNFfQ0KIyMjIENyZWF0aW5nIFdvcmtpbmcgTG9uZyBEYXRhDQojIEltcG9ydGFuY2UgYW5kIFRydXN0DQppbXAudHJ1c3Q8LW1lcmdlKHRMb25nLGltcExvbmcsYnk9YygiR29hbCIsIlBJTiIpKQ0KIyBBZGRpbmcgcmVseQ0KaW1wLnRydXN0LnJlbHk8LW1lcmdlKGltcC50cnVzdCxyTG9uZyxieT1jKCJHb2FsIiwiUElOIikpDQojIEFkZGluZyByZWxldmFuY2UgdG8gc3RyZW5ndGgNCmltcC50cnVzdC5yZWx5LnN0cjwtbWVyZ2UoaW1wLnRydXN0LnJlbHksc3JlbExvbmcsYnk9YygiR29hbCIsIlBJTiIpKQ0KIyBBZGRpbmcgcmVsZXZhbmNlIHRvIHdlYWtuZXNzDQpkYXRhMzwtbWVyZ2UoaW1wLnRydXN0LnJlbHkuc3RyLHdyZWxMb25nLGJ5PWMoIkdvYWwiLCJQSU4iKSkNCg0KIyBDb252ZXJ0aW5nIGdvYWwgdmFyaWFibGUgdG8gZmFjdG9yIGZvciBhbmFseXNlcw0KZGF0YTMkR29hbDwtYXMuZmFjdG9yKGRhdGEzJEdvYWwpDQoNCiMgQWRkaW5nIEZhY3RvciBJbmRpY2F0aW5nIE1vc3QgdnMgTGVhc3QgSW1wb3J0YW50IFByb2plY3RzDQpkYXRhMyRpbXBDYXQ8LWlmZWxzZShkYXRhMyRHb2FsPT0iR29hbDEiLCAxLA0KICAgICAgICAgICAgICBpZmVsc2UoZGF0YTMkR29hbD09IkdvYWwyIiwgMSwNCiAgICAgICAgICAgICAgaWZlbHNlKGRhdGEzJEdvYWw9PSJHb2FsMyIsIDEsDQogICAgICAgICAgICAgIGlmZWxzZShkYXRhMyRHb2FsPT0iR29hbDQiLCAwLA0KICAgICAgICAgICAgICBpZmVsc2UoZGF0YTMkR29hbD09IkdvYWw1IiwgMCwNCiAgICAgICAgICAgICAgaWZlbHNlKGRhdGEzJEdvYWw9PSJHb2FsNiIsIDAsTkEpKSkpKSkNCiMgQ29udmVydGluZyB0byBGYWN0b3INCmRhdGEzJGltcENhdDwtYXMuZmFjdG9yKGRhdGEzJGltcENhdCkNCg0KZGF0YTMkaW1wQ2F0PC1mYWN0b3IoZGF0YTMkaW1wQ2F0LA0KICAgICAgICAgICAgICAgICAgICAgbGV2ZWxzPWMoMCwxKSwNCiAgICAgICAgICAgICAgICAgICAgIGxhYmVscz1jKCJMZWFzdCBJbXBvcnRhbnQiLCJNb3N0IEltcG9ydGFudCIpKQ0KYGBgDQoNCk5vdyBsZXQncyBjaGVjayBvdXIgbmV3IGRhdGFmcmFtZSB0byBtYWtlIHN1cmUgYWxsIG91ciB2YXJpYWJsZXMgYXJlIHRoZXJlIGFuZCB0aGF0IHRoZXkncmUgaW4gdGhlIHByb3BlciBmb3JtYXQuDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQpzdHIoZGF0YTMpDQoNCmhlYWQoZGF0YTMpDQoNCnRhaWwoZGF0YTMpDQpgYGANCg0KTm93IHRoYXQgd2UgaGF2ZSB0aGUgZGF0YSBpbiB0aGUgYXBwcm9wcmlhdGUgZm9ybWF0LCB3ZSBvbmx5IGhhdmUgYSBjb3VwbGUgbW9yZSBwcmUtcHJvY2Vzc2luZyBzdGVwcy4gRmlyc3QsIHdlIG5lZWQgdG8gY2VudGVyIG91ciBwcmVkaWN0b3IgdmFyaWFibGVzLg0KDQpUaGVyZSBhcmUgdHdvIHdheXMgSSBjYW4gY2hvb3NlIHRvIGNlbnRlciBteSBwcmVkaWN0b3IgdmFyaWFibGVzLCBieSAqKnBhcnRpY2lwYW50Kiogb3IgKipnbG9iYWxseSoqLiAqKkdsb2JhbGx5LWNlbnRlcmVkKiogdmFyaWFibGVzIHdpbGwgc3VidHJhY3QgdGhlICoqZ3JhbmQgbWVhbioqLCBvciBvdmVyYWxsIGF2ZXJhZ2Ugb2YgdGhlIHZhcmlhYmxlLCBmcm9tIGVhY2ggcGFydGljaXBhbnQncyB2YWx1ZS4gVGhlIGVuZCByZXN1bHQgd2lsbCBiZSB0aGF0IHRoZSBhdmVyYWdlIHZhbHVlIG9mIHRoYXQgdmFyaWFibGUgYWNyb3NzIGFsbCBwYXJ0aWNpcGFudHMgd2lsbCBiZSAwLiAqKlBhcnRpY2lwYW50LWNlbnRlcmVkKiogdmFyaWFibGVzIHN1YnRyYWN0ICplYWNoIHBhcnRpY2lwYW50J3MqIG1lYW4gZnJvbSBlYWNoIG9mIHRoZWlyIHZhbHVlcy4gVGhlIGVuZCByZXN1bHQgb2YgKnRoaXMqIHByb2Nlc3Mgd2lsbCBiZSB0aGF0IHRoZSBhdmVyYWdlIGZvciBlYWNoIHBhcnRpY2lwYW50IG9uIGVhY2ggdmFyaWFibGUgaXMgMC4gRWFjaCBvZiB0aGVzZSBjZW50ZXJpbmcgc3RyYXRlZ2llcyB0ZWxscyBhIGRpZmZlcmVudCBzdG9yeSwgc28gaXQncyBpbXBvcnRhbnQgdG8gY2hvb3NlIHdoaWNoZXZlciBvbmUgbWFrZXMgdGhlIG1vc3Qgc2Vuc2UgZm9yIHlvdXIgcmVzZWFyY2ggcXVlc3Rpb24uIEluIHRoaXMgY2FzZSwgKipwYXJ0aWNpcGFudC1jZW50ZXJlZCoqIHZhcmlhYmxlcyBtYWtlcyB0aGUgbW9zdCBzZW5zZS4gU28gdGhhdCdzIHdoYXQgd2UncmUgZ29pbmcgdG8gZG8hDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQojIyBDZW50ZXJpbmcgSVZzIGJ5IFNzIA0KIyBSZWxldmFuY2UgdG8gU3RyZW5ndGgNCiMgTWVhbiBvZiBSZWxldmFuY2UgdG8gU3RyZW5ndGgNCmRhdGEzPC1kZHBseShkYXRhMywuKFBJTiksIHBseXI6Om11dGF0ZSwgclN0ck1lYW4gPSBtZWFuKFN0UmVsKSkNCiMgUGFydGljaXBhbnQtY2VudGVyZWQgUmVsZXZhbmNlIHRvIFN0cmVuZ3RoDQpkYXRhMyRTdHJSZWxDPC1kYXRhMyRTdFJlbC1kYXRhMyRyU3RyTWVhbg0KIyBHbG9iYWxseS1jZW50ZXJlZCBSZWxldmFuY2UgdG8gU3RyZW5ndGgNCmRhdGEzJFN0clJlbF9HbG9iQyA8LSBzY2FsZShkYXRhMyRTdFJlbCwgc2NhbGUgPSBGQUxTRSlbLF0NCmBgYA0KDQpgYGB7ciwgd2FybmluZyA9IEZBTFNFLCBlY2hvID0gRkFMU0V9DQojIFJlbGV2YW5jZSB0byBXZWFrbmVzcw0KZGF0YTM8LWRkcGx5KGRhdGEzLC4oUElOKSwgcGx5cjo6bXV0YXRlLCByV2Vha01lYW4gPSBtZWFuKFdlYWtSZWwpKQ0KZGF0YTMkV2Vha1JlbEM8LWRhdGEzJFdlYWtSZWwtZGF0YTMkcldlYWtNZWFuDQpkYXRhMyRXZWFrUmVsX0dsb2JDIDwtIHNjYWxlKGRhdGEzJFdlYWtSZWwsIHNjYWxlID0gRkFMU0UpWyxdDQoNCiMgSW1wb3J0YW5jZQ0KZGF0YTM8LWRkcGx5KGRhdGEzLC4oUElOKSwgcGx5cjo6bXV0YXRlLCBJbXBDID0gbWVhbihJbXBvcnRhbmNlKSkNCmRhdGEzJEltcG9ydGFuY2VDIDwtZGF0YTMkSW1wb3J0YW5jZS1kYXRhMyRJbXBDDQpkYXRhMyRJbXBfR2xvYkMgPC0gc2NhbGUoZGF0YTMkSW1wb3J0YW5jZSwgc2NhbGUgPSBGQUxTRSlbLF0NCg0KYGBgDQoNCk5vdyB0aGF0IHdlJ3ZlIGNlbnRlcmVkIG91ciBwcmVkaWN0b3JzLCBsZXQncyBjaGVjayB3aGV0aGVyIG91ciB0d28gcXVlc3Rpb25zIHRoYXQgYXJlIHRvIG1ha2UgdXAgb3VyIGNvbXBvc2l0ZSBtZWFzdXJlIG9mIGdvYWwtc3BlY2lmaWMgdHJ1c3QgYXJlIHN1ZmZpY2llbnRseSBjb3JyZWxhdGVkLiBJbiBvdGhlciB3b3JkcywgSSB3YW50IHRvIGF2ZXJhZ2UgdGhlIHJlc3BvbnNlcyB0byB0aGUgcXVlc3Rpb24gIlRvIHdoYXQgZXh0ZW50IHdvdWxkIHlvdSAqdHJ1c3QqIHlvdXIgYmVzdCBmcmllbmQiIHdpdGggdGhlIHJlc3BvbnNlcyB0byB0aGUgcXVlc3Rpb24gIlRvIHdoYXQgZXh0ZW50IHdvdWxkIHlvdSBiZSB3aWxsaW5nIHRvICpyZWx5KiBvbiB5b3VyIGJlc3QgZnJpZW5kPyIgSG93ZXZlciwgaWYgdGhlc2UgaXRlbXMgZG8gbm90IGFjdHVhbGx5IG1lYXN1cmUgdGhlIHNhbWUgdGhpbmcgKGkuZS4sIHRoZSBjb3JyZWxhdGlvbiBpcyByZWFsbHkgbG93KSwgdGhlbiBJIHNob3VsZG4ndCBhdmVyYWdlIHRoZW0gdG9nZXRoZXIuIFNvIGxldCdzIGxvb2sgcmVhbCBxdWljay4NCg0KYGBge3IsIHdhcm5pbmcgPSBGQUxTRX0NCmNvci50ZXN0KGRhdGEzJFRydXN0LGRhdGEzJFJlbHksIHVzZSA9ICJwYWlyd2lzZS5jb21wbGV0ZS5vYnMiKQ0KYGBgDQoNCk9rLiBUaGV5J3JlIGNvcnJlbGF0ZWQgYXQgYWJvdXQgMC44MCwgd2hpY2ggaXMgbm90IHRoZSBiZXN0LCBidXQgaXQgZG9lcyBmYWxsIHdpdGhpbiB0aGUgcmFuZ2UgdGhhdCBtb3N0IGNvbnNpZGVyIGFwcHJvcHJpYXRlIGZvciBhdmVyYWdpbmcuIFNvLCBub3cgSSdsbCBkbyB0aGF0IGhlcmUuDQoNCmBgYHtyLCB3YXJuaW5nID0gRkFMU0V9DQpkYXRhMyR0cnVzdFJlbHkgPC0gKGRhdGEzJFRydXN0K2RhdGEzJFJlbHkpLzINCmBgYA0KDQpQZXJmZWN0ISBOb3cgd2UncmUgcmVhZHkgdG8gZXhwbG9yZSBhbmQgYW5hbHl6aW5nIG91ciBkYXRhIQ0KPGJyLz48YnIvPjxici8+PGJyLz4NCg0KDQoNCg0KIyBQbG90dGluZw0KQSBjZW50cmFsIHRlbmV0IG9mIHRoZSB0aGVvcnkgSSdtIHRlc3RpbmcgaXMgdGhhdCB0cnVzdCBpcyBub3Qgc3RhdGljIGFjcm9zcyB0aGUgY29udG91cnMgb2YgYSByZWxhdGlvbnNoaXAuIEluIG90aGVyIHdvcmRzLCBwZW9wbGUgY2FuIHRydXN0IGFuZCBkaXN0cnVzdCB0aGUgc2FtZSBwZXJzb24gZGVwZW5kaW5nIG9uIHRoZSBnb2FsLiBJZiB0aGF0J3MgdHJ1ZSwgdGhlbiB3ZSBzaG91bGQgYmUgYWJsZSB0byBzZWUgaXQgaW4gb3VyIGRhdGEuIEJlbG93LCBJIHJhbmRvbWx5IHNlbGVjdCA0IHBhcnRpY2lwYW50cyBhbmQgcGxvdCB0aGUgdHJ1c3QgdGhleSBwbGFjZSBpbiB0aGVpciBiZXN0IGZyaWVuZCBhY3Jvc3MgdGhlaXIgdGhyZWUgbW9zdCBhbmQgbGVhc3QgaW1wb3J0YW50IGdvYWxzDQoNCmBgYHtyLCAsIGVjaG89RkFMU0UsIG91dC53aWR0aD0nLjQ5XFxsaW5ld2lkdGgnLCBmaWcud2lkdGg9MywgZmlnLmhlaWdodD0zLjI1LGZpZy5zaG93PSdob2xkJyxmaWcuYWxpZ249J2NlbnRlcid9DQojIFNldCBzZWVkIHNvIGV2ZXJ5b25lIHNlZXMgdGhlIHNhbWUgdGhpbmcNCnNldC5zZWVkKDEwMSkNCiMgU2FtcGxlIDQgcmFuZG9tIFBJTlMNCmJ5R29hbFNhbXBsZTwtIHNhbXBsZShkYXRhMyRQSU4sNCkNCiMgU3Vic2V0IHRoZSBkYXRhIGZvciB0aGUgNCByYW5kb20gcGFydGljaXBhbnRzDQpieUdvYWxTYW1wbGUyPC1kYXRhM1tkYXRhMyRQSU4gJWluJSBieUdvYWxTYW1wbGUsXQ0KDQpieUdvYWwzIDwtZ2dwbG90KGRhdGEgPSBieUdvYWxTYW1wbGUyLCANCiAgYWVzKHggPSBHb2FsLCB5PXRydXN0UmVseSkpKw0KICBmYWNldF9ncmlkKHZhcnMoUElOKSkrDQogIGdlb21fcG9pbnQoYWVzKGNvbG91ciA9IFBJTikpKw0KICBnZW9tX2xpbmUoYWVzKGNvbG91ciA9IFBJTixncm91cCA9IDEpKSsNCiAgeGxhYigiR29hbCIpK3lsYWIoIlRydXN0IikrICMgYWRkIGxhYmVscw0KICB5bGltKC00LCA0KSsNCiAgdGhlbWVfYncoKSsNCiAgdGhlbWUocGFuZWwuYm9yZGVyID0gZWxlbWVudF9yZWN0KGZpbGwgPSBOQSwgY29sb3VyID0gIk5BIiksDQogICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgICBsZWdlbmQucG9zaXRpb24gPSAidG9wIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KYnlHb2FsMw0KYGBgDQoNCkItZS1hLXV0aWZ1bCEhIFdoZXJlYXMgc29tZSBwZW9wbGUgc2VlbSB0byBiZSBwcmV0dHkgY29uc2lzdGVudCBpbiB0aGVpciB0cnVzdCBpbiB0aGVpciBiZXN0IGZyaWVuZCwgb3RoZXJzIGFwcGVhciB0byBjYWxpYnJhdGUgdGhlaXIgdHJ1c3QgaW4gdGhlaXIgZnJpZW5kIGFjcm9zcyB0aGUgZ29hbHMgaW4gdGhlaXIgbGl2ZXMuDQoNCk5vdyB0aGF0IHdlJ3ZlIGNoZWNrZWQgdG8gc2VlIHdoZXRoZXIgdGhpcyB3YXMgYWxsIHByb2JhYmx5IGEgd2FzdGUgb2YgdGltZSBvciB3aGV0aGVyIHRoZXJlIG1pZ2h0IGJlIHNvbWVtdGhpbmcgdGhlcmUsIGxldCdzIGNoZWNrIG91dCB0aGUgb3RoZXIgdmFyaWFibGVzLg0KPGJyLz48YnIvPjxici8+DQoNCg0KDQojIyBIaXN0b2dyYW1zDQpPaywgbm93IHRoYXQgd2UndmUgY2VudGVyZWQgb3VyIGRhdGEsIGxldCdzIHRha2UgYSBsb29rIGF0IHRoZSBoaXN0b2dyYW1zIG9mIG91ciB2YXJpYWJsZXMuIEZpcnN0LCBsZXQncyBsb29rIGF0IHRoZSBkaXN0cmlidXRpb24gb2YgdGhlIHJlbGV2YW5jZSB0byBzdHJlbmd0aCBtZWFzdXJlLg0KPGJyLz48YnIvPjxici8+DQoNCg0KDQojIyMgUmVsZXZhbmNlIHRvIFN0cmVuZ3RoDQpgYGB7ciwgLCBlY2hvPUZBTFNFLCBvdXQud2lkdGg9Jy40OVxcbGluZXdpZHRoJywgZmlnLndpZHRoPTMsIGZpZy5oZWlnaHQ9My4yNSxmaWcuc2hvdz0naG9sZCcsZmlnLmFsaWduPSdjZW50ZXInfQ0KcmVsX3N0cl9IaXN0IDwtIGRhdGEzICU+JQ0KICBnZ3Bsb3QoYWVzKHggPSBTdFJlbCkpICsNCiAgZ2VvbV9oaXN0b2dyYW0oKSArDQogIHhsYWIoIlJlbGV2YW5jZSB0byBTdHJlbmd0aCIpK3lsYWIoIkNvdW50IikgKyAjIGFkZCBsYWJlbHMgDQogIHRoZW1lX2J3KCkgKw0KICB0aGVtZShwYW5lbC5ncmlkLm1ham9yID0gZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ncmlkLm1pbm9yID0gZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ib3JkZXIgPSBlbGVtZW50X3JlY3QoZmlsbCA9IE5BLCBjb2xvdXIgPSAiTkEiKSwNCiAgICAgICAgYXhpcy5saW5lID0gZWxlbWVudF9saW5lKHNpemUgPSAxLCBjb2xvdXIgPSAiZ3JleTgwIiksDQogICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KcmVsX3N0cl9IaXN0DQpgYGANCg0KVGhhdCBsb29va3MgZGVjZW50LiBJdCdzIGEgYml0IHBvc2l0aXZlbHktc2tld2VkLCB3aGljaCBtZWFucyB0aGF0IHRoZWlyIGFyZSBtb3JlIHZhbHVlcyBvbiB0aGUgbG93ZXIgZW5kIG9mIHRoZSBzY2FsZSB0aGFuIHRoZSBoaWdoZXIgZW5kLCBidXQgaXQgZG9lc24ndCBsb29rIHRlcnJpYmxlLiBOb3cgbGV0J3MgdGFrZSBhIGxvb2sgYXQgdGhlIHJlbGV2YW5jZSB0byB3ZWFrbmVzcyBtZWFzdXJlDQo8YnIvPjxici8+DQoNCg0KIyMjIFJlbGV2YW5jZSB0byBXZWFrbmVzcw0KYGBge3IsICwgZWNobz1GQUxTRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCnJlbF93ZWFrX0hpc3QgPC0gZGF0YTMgJT4lDQogIGdncGxvdChhZXMoeCA9IFdlYWtSZWwpKSArDQogIGdlb21faGlzdG9ncmFtKCkgKw0KICB4bGFiKCJSZWxldmFuY2UgdG8gV2Vha25lc3MiKSt5bGFiKCJDb3VudCIpICsgIyBhZGQgbGFiZWxzIA0KICB0aGVtZV9idygpICsNCiAgdGhlbWUocGFuZWwuZ3JpZC5tYWpvciA9IGVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICBwYW5lbC5ncmlkLm1pbm9yID0gZWxlbWVudF9ibGFuaygpLA0KICAgICAgIHBhbmVsLmJvcmRlciA9IGVsZW1lbnRfcmVjdChmaWxsID0gTkEsIGNvbG91ciA9ICJOQSIpLA0KICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIiwNCiAgICAgICBsZWdlbmQudGl0bGUgPSBlbGVtZW50X2JsYW5rKCkpDQpyZWxfd2Vha19IaXN0DQpgYGANCg0KVGhhdCBpcyAqbXVjaCogd29yc2UuIE5vdGljZSBob3cgbmVhcmx5IGFsbCBvZiB0aGUgdmFsdWVzIGFyZSBhdCB0aGUgbG93ZXN0IGVuZCBvZiB0aGUgc2NhbGU/IE5vdCBvbmx5IGlzIHRoaXMgZXh0cmVtZWx5IHBvc2l0aXZlbHktc2tld2VkLCBpdCBhbHNvIGxvb2tzIGxpa2Ugd2UncmUgc2VlaW5nIGEgKipmbG9vciBlZmZlY3QqKi4gQSAqKkZsb29yIGVmZmVjdCoqIGlzIHdoZW4gdGhlIGRpc3RyaWJ1dGlvbiBvZiB5b3VyIHZhcmlhYmxlIGlzIGNsdXN0ZXJlZCBhdCB0aGUgbG93ZXIgYm91bmQgb2YgdGhlIHZhcmlhYmxlIHJhbmdlLiBUaGlzIGlzIG5vdCBhIGdvb2QgZGlzdHJpYnV0aW9uLCBhbmQgaXQgdGVsbHMgdXMgdGhhdCBhbnkgcG90ZW50aWFsIGZhaWx1cmUgdG8gZmluZCBhbiBlZmZlY3QgbWF5IGJlIGR1ZSB0byB0aGUgaHlwb3RoZXNpcyAqb3IqIHRoZSAqKmZsb29yIGVmZmVjdCoqLiBUaGF0J3Mgbm90IGdvb2QsIGJ1dCBpdCBpcyB3aGF0IHdlIGhhdmUsIHNvIHdlJ2xsIHNlZSB3aGF0IHdlIHNlZS4NCg0KRmluYWxseSwgbGV0J3MgY2hlY2sgb3V0IHRoZSBkaXN0cmlidXRpb24gb2YgdGhlIGNvbnRpbnVvdXMgbWVhc3VyZSBvZiBnb2FsIGltcG9ydGFuY2UuDQo8YnIvPjxici8+DQoNCg0KIyMjIEdvYWwgSW1wb3J0YW5jZQ0KYGBge3IsICwgZWNobz1GQUxTRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCnJlbF93ZWFrX0hpc3QgPC0gZGF0YTMgJT4lDQogIGdncGxvdChhZXMoeCA9IEltcG9ydGFuY2UpKSArDQogIGdlb21faGlzdG9ncmFtKCkgKw0KICB4bGFiKCJHb2FsIEltcG9ydGFuY2UiKSt5bGFiKCJDb3VudCIpICsgIyBhZGQgbGFiZWxzIA0KICB0aGVtZV9idygpICsNCiAgdGhlbWUocGFuZWwuZ3JpZC5tYWpvciA9IGVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICBwYW5lbC5ncmlkLm1pbm9yID0gZWxlbWVudF9ibGFuaygpLA0KICAgICAgIHBhbmVsLmJvcmRlciA9IGVsZW1lbnRfcmVjdChmaWxsID0gTkEsIGNvbG91ciA9ICJOQSIpLA0KICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIiwNCiAgICAgICBsZWdlbmQudGl0bGUgPSBlbGVtZW50X2JsYW5rKCkpDQpyZWxfd2Vha19IaXN0DQpgYGANCg0KSW4gY29udHJhc3QgdG8gdGhlIGxhc3QgdHdvIGhpc3RvZ3JhbXMsIHRoaXMgdmFyaWFibGUgaXMgYSBiaXQgKipuZWdhdGl2ZWx5LXNrZXdlZCoqLCB3aGljaCBtZWFucyB0aGF0IG1vc3Qgb2YgdGhlIHZhbHVlcyBhcmUgYXQgdGhlIGhpZ2hlciBlbmQgb2YgdGhlIHNjYWxlLiBIb3dldmVyLCBsaWtlIHRoZSByZWxldmFuY2UgdG8gc3RyZW5ndGggbWVhc3VyZSwgdGhpcyBkaXN0cmlidXRpb24gaXMgbm90IHdvcnJpc29tZS4gDQoNCk5vdyB0aGF0IHdlJ3ZlIGNoZWNrZWQgdGhlIGRpc3RyaWJ1dGlvbnMgb2Ygb3VyIHByZWRpY3RvciB2YXJpYWJsZXMsIGxldCdzIHBsb3Qgb3V0IHRoZSByZWxhdGlvbnNoaXBzIHdlIHBsYW4gdG8gdGVzdC4NCjxici8+PGJyLz48YnIvPg0KDQoNCg0KIyMgUHJlZGljdGVkIFJlbGF0aW9uc2hpcHMNCkJlZm9yZSB3ZSBwbG90IHRoZSBoeXBvdGhlc2l6ZWQgcmVsYXRpb25zaGlwcywgbGV0J3MgZmlyc3QgY2hlY2sgdG8gbWFrZSBzdXJlIHRoYXQgcGFydGljaXBhbnRzJyBtb3N0IGltcG9ydGFudCBnb2FscyB3ZXJlIGFjdHVhbGx5IG1vcmUgaW1wb3J0YW50IHRoYW4gdGhlaXIgbGVhc3QgaW1wb3J0YW50IGdvYWxzLg0KPGJyLz48YnIvPg0KDQoNCiMjIyBNYW5pcHVsYXRpb24gQ2hlY2sNCmBgYHtyLCAsIGVjaG89RkFMU0UsIG91dC53aWR0aD0nLjQ5XFxsaW5ld2lkdGgnLCBmaWcud2lkdGg9MywgZmlnLmhlaWdodD0zLjI1LGZpZy5zaG93PSdob2xkJyxmaWcuYWxpZ249J2NlbnRlcid9DQppbXBDaGVjayA8LSBnZ3Bsb3QoZGF0YSA9IGRhdGEzLGFlcyh4ID0gR29hbCwgeT1JbXBvcnRhbmNlQykpKw0KICBnZW9tX3BvaW50KGFlcyhjb2xvdXIgPSBQSU4pKSsNCiAgZ2VvbV9zbW9vdGgobWV0aG9kID0gImxtIiwgc2UgPSBULCBhZXMoZ3JvdXAgPSBpbXBDYXQsIGNvbG91cj1pbXBDYXQpKSsNCiAgeGxhYigiR29hbCIpK3lsYWIoIkltcG9ydGFuY2UiKSsgIyBhZGQgbGFiZWxzDQogIHlsaW0oLTQsIDQpKyN4bGltKC00LCA0KSsNCiAgdGhlbWVfYncoKSsNCiAgdGhlbWUocGFuZWwuZ3JpZC5tYWpvcj1lbGVtZW50X2JsYW5rKCksDQogICAgICAgIHBhbmVsLmdyaWQubWlub3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ib3JkZXIgPSBlbGVtZW50X3JlY3QoZmlsbCA9IE5BLCBjb2xvdXIgPSAiTkEiKSwNCiAgICAgICAgYXhpcy5saW5lID0gZWxlbWVudF9saW5lKHNpemUgPSAxLCBjb2xvdXIgPSAiZ3JleTgwIiksDQogICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KaW1wQ2hlY2sNCmBgYA0KDQpQZXJmZWN0LiBQYXJ0aWNpcGFudHMgY29tcGxldGVkIHRoZSBzdHVkeSBhcyBleHBlY3RlZCEgTm93IGxldCdzIGNoZWNrIG91dCBvdXIgaHlwb3RoZXNlcy4NCg0KVGhlIGZpcnN0IGh5cG90aGVzaXMgd2FzIHRoYXQgcGFydGljaXBhbnRzIHdvdWxkIHRydXN0IHRoZWlyIGJlc3QgZnJpZW5kIGxlc3MgZm9yIG1vcmUgaW1wb3J0YW50IHRoYW4gbGVzcyBpbXBvcnRhbnQgZ29hbHMuIExldCdzIHNlZSBpZiB0aGF0J3Mgd2hhdCB0aGUgcmVsYXRpb25zaGlwIGxvb2tzIGxpa2UuDQo8YnIvPjxici8+DQoNCg0KIyMjIFRydXN0IEJ5IEltcG9ydGFuY2UNCmBgYHtyLCAsIGVjaG89RkFMU0UsIG91dC53aWR0aD0nLjQ5XFxsaW5ld2lkdGgnLCBmaWcud2lkdGg9MywgZmlnLmhlaWdodD0zLjI1LGZpZy5zaG93PSdob2xkJyxmaWcuYWxpZ249J2NlbnRlcid9DQojIEdyYXBoaW5nIFRydXN0IGJ5IEltcG9ydGFuY2UNCkltcFRydXN0IDwtIGdncGxvdChkYXRhID0gZGF0YTMsIA0KICBhZXMoeCA9IEltcG9ydGFuY2VDLCB5PXRydXN0UmVseSkpKw0KICAjZ2VvbV9wb2ludChhZXMoY29sb3VyID0gUElOKSkrDQogIGdlb21fc21vb3RoKG1ldGhvZD0ibG0iLCBzZSA9IFQpKyMsIGFlcyhncm91cCA9IFBJTikpKyMgd2UgYWRkIGdyb3VwIGxldmVsDQogIHhsYWIoIkltcG9ydGFuY2UiKSt5bGFiKCJUcnVzdCIpKyAjIGFkZCBsYWJlbHMNCiAgeWxpbSgtNCwgNCkrDQogICN4bGltKC00LCA0KSsNCiAgdGhlbWVfYncoKSsNCiAgdGhlbWUocGFuZWwuZ3JpZC5tYWpvcj1lbGVtZW50X2JsYW5rKCksDQogICAgICAgIHBhbmVsLmdyaWQubWlub3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ib3JkZXIgPSBlbGVtZW50X3JlY3QoZmlsbCA9IE5BLCBjb2xvdXIgPSAiTkEiKSwNCiAgICAgICAgYXhpcy5saW5lID0gZWxlbWVudF9saW5lKHNpemUgPSAxLCBjb2xvdXIgPSAiZ3JleTgwIiksDQogICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KSW1wVHJ1c3QNCmBgYA0KDQpXZWxsLCB0aGVyZSBkb2Vzbid0IGFwcGVhciB0byBiZSBtdWNoIG9mIGEgcmVsYXRpb25zaGlwIHRoZXJlLiBJbiBmYWN0LCBpdCBraW5kYSBsb29rcyBsaWtlIHRoZSBzbG9wZSBpcyBpbiB0aGUgb3Bwb3NpdGUgZGlyZWN0aW9uIHRoYW4gcHJlZGljdGVkLiBUaGlzIGlzIGRlZmluaXRlbHkgc29tZXRoaW5nIHRvIGxvb2sgZm9yIGluIHRoZSBzdGF0cyB3ZSdsbCBydW4gaW4gYSBiaXQuDQoNClRoZSBzZWNvbmQgaHlwb3RoZXNpcyB3YXMgdGhhdCBwYXJ0aWNpcGFudHMgd291bGQgdHJ1c3QgdGhlaXIgYmVzdCBmcmllbmQgKm1vcmUqIHRoZSBtb3JlIHRoZWlyIGZyaWVuZCdzIHN0cmVuZ3RoIHdhcyByZWxldmFudCB0byB0aGUgZ29hbC4gTGV0J3MgdGFrZSBhIGxvb2suDQo8YnIvPjxici8+DQoNCg0KIyMjIFRydXN0IEJ5IFN0cmVuZ3RoDQpgYGB7ciwgLCBlY2hvPUZBTFNFLCBvdXQud2lkdGg9Jy40OVxcbGluZXdpZHRoJywgZmlnLndpZHRoPTMsIGZpZy5oZWlnaHQ9My4yNSxmaWcuc2hvdz0naG9sZCcsZmlnLmFsaWduPSdjZW50ZXInfQ0KcmVsU3RyIDwtIGdncGxvdChkYXRhID0gZGF0YTMsIA0KICBhZXMoeCA9IFN0clJlbEMsIHk9dHJ1c3RSZWx5KSkrIA0KICBnZW9tX3Ntb290aChtZXRob2QgPSAibG0iLCBzZSA9IFQpKw0KICB4bGFiKCJSZWxldmFuY2UgdG8gU3RyZW5ndGgiKSt5bGFiKCJUcnVzdCIpKyAjIGFkZCBsYWJlbHMNCiAgeWxpbSgtNCwgNCkrDQogIHRoZW1lX2J3KCkrDQogIHRoZW1lKHBhbmVsLmdyaWQubWFqb3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ncmlkLm1pbm9yPWVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICAgcGFuZWwuYm9yZGVyID0gZWxlbWVudF9yZWN0KGZpbGwgPSBOQSwgY29sb3VyID0gIk5BIiksDQogICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgICBsZWdlbmQucG9zaXRpb24gPSAidG9wIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KcmVsU3RyDQpgYGANCg0KVGhhdCBsb29rcyBsaWtlIGEgc3Ryb25nIHJlbGF0aW9uc2hpcCBpbiB0aGUgZGlyZWN0aW9uIHdlIHByZWRpY3RlZCEgWWF5ISEgDQoNClRoZSB0aGlyZCBwcmVkaWN0aW9uIHdhcyB0aGF0IHBhcnRpY2lwYW50cyB3b3VsZCB0cnVzdCB0aGVpciBiZXN0IGZyaWVuZCAqbGVzcyogdGhlIG1vcmUgdGhlaXIgZnJpZW5kJ3Mgd2Vha25lc3Mgd2FzIHJlbGV2YW50IHRvIHRoZSBnb2FsLg0KPGJyLz48YnIvPg0KDQoNCiMjIyBUcnVzdCBCeSBXZWFrbmVzcw0KYGBge3IsICwgZWNobz1GQUxTRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCnJlbFdlYWsgPC0gZ2dwbG90KGRhdGEgPSBkYXRhMywgDQogIGFlcyh4ID0gV2Vha1JlbEMsIHk9dHJ1c3RSZWx5KSkrIA0KICBnZW9tX3Ntb290aChtZXRob2QgPSAibG0iLCBzZSA9IFQpKw0KICB4bGFiKCJSZWxldmFuY2UgdG8gV2Vha25lc3MiKSt5bGFiKCJUcnVzdCIpKyAjIGFkZCBsYWJlbHMNCiAgeWxpbSgtNCwgNCkrDQogIHRoZW1lX2J3KCkrDQogIHRoZW1lKHBhbmVsLmdyaWQubWFqb3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ncmlkLm1pbm9yPWVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICAgcGFuZWwuYm9yZGVyID0gZWxlbWVudF9yZWN0KGZpbGwgPSBOQSwgY29sb3VyID0gIk5BIiksDQogICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgICBsZWdlbmQucG9zaXRpb24gPSAidG9wIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KcmVsV2Vhaw0KYGBgDQoNClRoYXQgbG9va3MgbGlrZSBhIHdlYWsgcmVsYXRpb25zaGlwIGJ1dCBhZ2FpbiBpbiB0aGUgb3Bwb3NpdGUgZGlyZWN0aW9uIHRoYW4gcHJlZGljdGVkLiBUaGlzIGlzIGFub3RoZXIgZmluZGluZyB3ZSdsbCBrZWVwIGEgc2hhcnAgZXllIG9uIGluIG91ciBhbmFseXNlcy4NCg0KVGhlIGZpbmFsIHR3byBoeXBvdGhlc2VzIHdlcmUgdGhhdCB0aGUgcmVsYXRpb25zaGlwcyBiZXR3ZWVuIHRoZSByZWxldmFuY2UgdG8gc3RyZW5ndGggYW5kIHRoZSByZWxldmFuY2UgdG8gd2Vha25lc3Mgb24gZ29hbC1zcGVjaWZpYyB0cnVzdCB3b3VsZCBvbmx5IHNob3cgdXAgZm9yIG1vcmUgaW1wb3J0YW50IGdvYWxzLiBUaGVyZSBzaG91bGQgYmUgbm8gcmVsYXRpb25zaGlwIGJldHdlZW4gdGhlIHJlbGV2YW5jZSB0byBzdHJlbmd0aCBhbmQgdGhlIHJlbGV2YW5jZSB0byB3ZWFrbmVzcyBvbiBnb2FsLXNwZWNpZmljIHRydXN0IGZvciBsZXNzIGltcG9ydGFudCBnb2Fscy4gTmV4dCBJIHBsb3QgdGhvc2UgcHJlZGljdGlvbnMuIFdlJ2xsIGZpcnN0IHRha2UgYSBsb29rIGF0IHRoZSBpbnRlcmFjdGlvbiBiZXR3ZWVuIGdvYWwgaW1wb3J0YW5jZSBhbmQgdGhlIHJlbGV2YW5jZSB0byBzdHJlbmd0aCBiZWZvcmUgZXhhbWluaW5nIHRoZSBpbnRlcmFjdGlvbiBiZXR3ZWVuIGdvYWwgaW1wb3J0YW5jZSBhbmQgdGhlIHJlbGV2YW5jZSB0byB3ZWFrbmVzcy4NCjxici8+PGJyLz4NCg0KDQojIyMgSW50ZXJhY3Rpb25zDQpgYGB7ciwgLCBlY2hvPUZBTFNFLCBvdXQud2lkdGg9Jy40OVxcbGluZXdpZHRoJywgZmlnLndpZHRoPTMsIGZpZy5oZWlnaHQ9My4yNSxmaWcuc2hvdz0naG9sZCcsZmlnLmFsaWduPSdjZW50ZXInfQ0KcmVsU3RySW1wIDwtIGdncGxvdChkYXRhID0gZGF0YTMsIA0KICBhZXMoeCA9IFN0clJlbEMsIHk9dHJ1c3RSZWx5KSkrIA0KICBnZW9tX3Ntb290aChtZXRob2QgPSAibG0iLCBzZSA9IFQsIGFlcyhncm91cCA9IGltcENhdCwgY29sb3VyPWltcENhdCkpKyAjIGFkZCBncm91cCBsZXZlbA0KICB4bGFiKCJSZWxldmFuY2UgdG8gU3RyZW5ndGgiKSt5bGFiKCJUcnVzdCIpKyAjIGFkZCBsYWJlbHMNCiAgeWxpbSgtNCwgNCkrDQogIHRoZW1lX2J3KCkrDQogIHRoZW1lKHBhbmVsLmdyaWQubWFqb3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ncmlkLm1pbm9yPWVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICAgcGFuZWwuYm9yZGVyID0gZWxlbWVudF9yZWN0KGZpbGwgPSBOQSwgY29sb3VyID0gIk5BIiksDQogICAgICAgIGF4aXMubGluZSA9IGVsZW1lbnRfbGluZShzaXplID0gMSwgY29sb3VyID0gImdyZXk4MCIpLA0KICAgICAgICBsZWdlbmQucG9zaXRpb24gPSAidG9wIiwNCiAgICAgICAgbGVnZW5kLnRpdGxlID0gZWxlbWVudF9ibGFuaygpKQ0KcmVsU3RySW1wDQpgYGANCg0KYGBge3IsICwgZWNobz1GQUxTRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCnJlbFdlYWtJbXAgPC0gZ2dwbG90KGRhdGEgPSBkYXRhMywgDQogIGFlcyh4ID0gV2Vha1JlbEMsIHk9dHJ1c3RSZWx5KSkrIA0KICBnZW9tX3Ntb290aChtZXRob2QgPSAibG0iLCBzZSA9IFQsIGFlcyhncm91cCA9IGltcENhdCwgY29sb3VyPWltcENhdCkpKyMgd2UgYWRkIGdyb3VwIGxldmVsDQogIHhsYWIoIlJlbGV2YW5jZSB0byBXZWFrbmVzcyIpK3lsYWIoIlRydXN0IikrICMgYWRkIGxhYmVscw0KICB5bGltKC00LCA0KSsNCiAgdGhlbWVfYncoKSsNCiAgdGhlbWUocGFuZWwuZ3JpZC5tYWpvcj1lbGVtZW50X2JsYW5rKCksDQogICAgICAgIHBhbmVsLmdyaWQubWlub3I9ZWxlbWVudF9ibGFuaygpLA0KICAgICAgICBwYW5lbC5ib3JkZXIgPSBlbGVtZW50X3JlY3QoZmlsbCA9IE5BLCBjb2xvdXIgPSAiTkEiKSwNCiAgICAgICAgYXhpcy5saW5lID0gZWxlbWVudF9saW5lKHNpemUgPSAxLCBjb2xvdXIgPSAiZ3JleTgwIiksDQogICAgICAgIGxlZ2VuZC5wb3NpdGlvbiA9ICJ0b3AiLA0KICAgICAgICBsZWdlbmQudGl0bGUgPSBlbGVtZW50X2JsYW5rKCkpDQpyZWxXZWFrSW1wDQpgYGANCg0KV2VscC4gSXQgbG9va3MgbGlrZSBuZWl0aGVyIHByZWRpY3Rpb24gd2FzIHN1cHBvcnRlZC4gVGltZSB0byBnbyBydW4gdGhlIHN0YXRpc3RpY2FsIGFuYWx5c2VzIHRvIGNoZWNrIHdoYXQgb3VyIGdyYXBocyBhcmUgdGVsbGluZyB1cy4NCjxici8+PGJyLz48YnIvPjxici8+DQoNCg0KDQoNCiMgQW5hbHlzZXMNCk5vdyB0aGF0IHdlJ3ZlIGdyYXBoZWQgb3VyIGRhdGEgYW5kIGdvdHRlbiBpbnNpZ2h0IGludG8gb3VyIHZhcmlhYmxlcycgZGlzdHJpYnV0aW9ucyBhbmQgdGhlIHJlbGF0aW9uc2hpcHMgYmV0d2VlbiBvdXIgcHJlZGljdG9yIGFuZCBjcml0ZXJpb24gdmFyaWFibGVzLCBpdCdzIHRpbWUgdG8gcnVuIHN0YXRpc3RpY2FsIGFuYWx5c2VzIHRvIGZvcm1hbGx5IHRlc3Qgb3VyIGh5cG90aGVzZXMuIA0KDQpUaGUgYW5hbHlzZXMgdGhhdCBJIHdpbGwgZG8gYmVsb3cgYXJlIGxpbmVhciBtdWx0aWxldmVsIChvciBtaXhlZCBlZmZlY3RzKSBtb2RlbHMgKE1MTXMpLiBUaGVzZSBhbmFseXNlcyB3aWxsIGFsbG93IG1lIHRvIG1vZGVsIHRoZSByYW5kb20gdmFyaWFuY2UgdGhhdCBpcyBjYXVzZWQgYnkgb3VyIHBhcnRpY2lwYW50cyByZXBvcnRpbmcgZGlmZmVyZW50IGF2ZXJhZ2UgbGV2ZWxzIG9mIHRydXN0IGluIHRoZWlyIGJlc3QgZnJpZW5kIChyYW5kb20gaW50ZXJjZXB0KSBhbmQgZGlmZmVyZW50IHJlbGF0aW9uc2hpcHMgYmV0d2VlZW4gZ29hbCBpbXBvcnRhbmNlIGFuZCBnb2FsLXNwZWNpZmljIHRydXN0IChyYW5kb20gc2xvcGUpLiANCg0KQXMgYSBzaWRlIG5vdGUsIHRoZSBtb3N0IGFwcHJvcHJpYXRlIGFuYWx5c2VzIGZvciB0aGVzZSBkYXRhIGFyZSBhY3R1YWxseSBvcmRpbmFsIGxvZ2lzdGljIG11bHRpbGV2ZWwgbW9kZWxzLiBUaGUgY3JpdGVyaW9uIHZhcmlhYmxlLCBnb2FsLXNwZWNpZmljIHRydXN0LCBpcyBvbiBhbiAqKm9yZGluYWwgc2NhbGUqKi4gT3JkaW5hbCBzY2FsZXMgYXJlIHdoZXJlIHRoZSBkaXN0YW5jZSBiZXR3ZWVuIHNjYWxlIHBvaW50cyBhcmUgbm90IGV2ZW4uIEJ5IGNvbnRyYXN0LCBpbiAqKmludGVydmFsKiogb3IgKipyYXRpbyBzY2FsZXMqKiwgdGhlIGRpc3RhbmNlIGJldHdlZW4gc2NhbGUgcG9pbnRzIGlzIHRoZSBzYW1lLiBBbiBleGFtcGxlIG9mIGFuIGludGVydmFsIHNjYWxlIGlzIHRlbXBlcmF0dXJlIGluIGRlZ3JlZXMgRmFocmVuaGVpdC4gVGhlIGRpZmZlcmVuY2UgYmV0d2VlbiAxJF5cY2lyYyQgYW5kIDIkXlxjaXJjJCBGYWhyZW5oZWl0IGlzIHRoZSBzYW1lIGFzIHRoZSBkaWZmZXJlbmNlIGJldHdlZW4gMTAxJF5cY2lyYyQgYW5kIDEwMiReXGNpcmMkIEZhaHJlbmhlaXQuIEJ5IGNvbnRyYXN0LCBpcyB0aGUgZGlmZmVyZW5jZSBiZXR3ZWVuICJzbGlnaHRseSB0cnVzdCIgYW5kICJtb2RlcmF0ZWx5IHRydXN0IiB0aGUgc2FtZSBhcyB0aGUgZGlmZmVyZW5jZSBiZXR3ZWVuICJtb2RlcmF0ZWx5IHRydXN0IiBhbmQgInZlcnkgbXVjaCB0cnVzdD8iIEkgZG9uJ3Qga25vdywgYnV0IHByb2JhYmx5IG5vdC4gVGVjaG5pY2FsbHksIGxpbmVhciBNTE1zIHJlcXVpcmUgaW50ZXJ2YWwgb3IgcmF0aW8gY3JpdGVyaW9uIHZhcmlhYmxlcyB3aGVyZWFzIG9yZGluYWwgbG9naXN0aWMgTUxNcyByZXF1aXJlIG9yZGluYWwgY3JpdGVyaW9uIHZhcmlhYmxlcy4gSG93ZXZlciwgSSByYW4gYm90aCBzZXRzIG9mIGFuYWx5c2VzLCBhbmQgdGhlIGNvbmNsdXNpb25zIHJlbWFpbiB0aGUgc2FtZS4gQ29uc2VxdWVudGx5LCBJIGRlbW9uc3RyYXRlIGxpbmVhciBNTE1zIGhlcmUgYmVjYXVzZSB0aGV5IGFyZSBnZW5lcmFsbHkgZWFzaWVyIHRvIHVuZGVyc3RhbmQuDQoNClRoZXNlIGFuYWx5c2VzIGFyZSBhIGJpdCBjb21wbGljYXRlZCBhbmQgcmVxdWlyZSB1cyB0byBjYXJlZnVsbHkgbW9uaXRvciBjaGFuZ2VzIGluIG91ciBvdXRwdXQgYXMgYSBmdW5jaXRvbiBvZiBjaGFuZ2VzIGluIG91ciBmaXhlZCBhbmQgcmFuZG9tIGVmZmVjdHMuIEkgd2lsbCBleHBsYWluIGVhY2ggc3RlcC4NCjxici8+PGJyLz48YnIvPg0KDQoNCg0KIyMgUmFuZG9tIEVmZmVjdHMNClRoZSBmaXJzdCBzdGVwIGluIHJ1bm5pbmcgTUxNcyBpcyB0byBleGFtaW5lIHlvdXIgcmFuZG9tIHN0cnVjdHVyZS4gVG8gZG8gdGhpcywgd2Ugd2lsbCBpbmNsdWRlIG9ubHkgdGhlIGNyaXRlcmlvbiB2YXJpYWJsZSBhbmQgYW4gaW50ZXJjZXB0IGluIG91ciBtb2RlbCBhbmQgc3lzdGVtYXRpY2FsbHkgY2hhbmdlIG91ciByYW5kb20gZWZmZWN0cy4gVGhpcyBwYXJ0IG1pZ2h0IGJlIGEgYml0IGVhc2llciB0byB1bmRlcnN0YW5kIHdoaWxlIGRvaW5nIGl0IHRoYW4gbWUgZXhwbGFpbmluZyBpdCwgc28gbGV0J3MganVzdCBkaXZlIHJpZ2h0IGluLg0KDQpJbiB0aGlzIGZpcnN0IG1vZGVsLCBJIGFtIGdvaW5nIHRvIHVzZSB3aGF0J3MgY2FsbGVkIHRoZSBtYXhpbWFsIHJhbmRvbSBzdHJ1Y3R1cmUuIFRoZSBtYXhpbWFsIHN0cnVjdHVyZSBpbmNsdWRlcyB0aGUgcmFuZG9tIGludGVyY2VwdCAqYW5kKiB0aGUgcmFuZG9tIHNsb3BlLCBhbmQgaXMgb3VyIGJlc3QgbW9kZWwgYXQgcmVkdWNpbmcgb3VyIFR5cGUgSSBlcnJvciByYXRlICh3aGljaCBpcyB0aGUgcHJvYmFiaWxpdHkgb2YgaW5jb3JyZWN0bHkgc2F5aW5nIHRoZXJlIGlzIGEgcmVhbCBlZmZlY3Qgd2hlbiB0aGVyZSBpcyBpbiBmYWN0IG5vIGVmZmVjdCkuDQoNCmBgYHtyfQ0KbWF4X3JhbmRvbSA8LSBsbWVyKEltcG9ydGFuY2UgfiAxDQogICAgICAgICArICgxK2R1bW15KGltcENhdCl8UElOKSwgZGF0YSA9IGRhdGEzLCBSRU1MPUYpDQpzdW1tYXJ5KG1heF9yYW5kb20pDQpgYGANCg0KVGhlIGZpcnN0IHRoaW5nIHlvdSBzaG91bGQgbm90ZSBpcyB0aGUgd2FybmluZyB0aGF0IHRoZSBtb2RlbCBmYWlsZWQgdG8gY29udmVyZ2UuIFRoaXMgbWVhbnMgdGhhdCB0aGUgbWF4aW11bSBsaWtlbGlob29kIGVzdGltYXRpb24gcHJvY2VzcyAoYmV5b25kIHRoZSBzY29wZSBvZiB0aGlzIGV4cGxhbmF0aW9uKSBmYWlsZWQuIEEgd2lzZSBwZXJzb24gb25jZSB0b2xkIG1lIHRoYXQgYSBtb2RlbCB0aGF0IGRvZXMgbm90IHdvcmsgY2Fubm90IGJlIHRoZSBjb3JyZWN0IG1vZGVsLiBBbHRob3VnaCB3ZSdyZSBnZXR0aW5nIG51bWJlcnMgaGVyZSwgaXQncyBwcm9iYWJseSBiZXN0IHRvIHJlZHVjZSBvdXIgcmFuZG9tIHN0cnVjdHVyZS4gIFRoZSBzZWNvbmQgdGhpbmcgdG8gbm90ZSBpcyB0aGF0IHRoZSBjb3JyZWxhaXRvbiBiZXR3ZWVuIHRoZSByYW5kb20gaW50ZXJjZXB0IGFuZCB0aGUgcmFuZG9tIHNsb3BlIGlzIHZlcnkgaGlnaCAoLTAuOTkpLiBBIHBlcmZlY3QgY29ycmVsYXRpb24gKCsvLSAxLjAwKSBpcyB2ZXJ5IGJhZCBmb3Igb3VyIG1vZGVsLCBzbyB0aGF0IGdpdmVzIHVzIGZ1cnRoZXIgcmVhc29uIHRvIHJlZHVjZSBvdXIgcmFuZG9tIHN0cnVjdHVyZS4NCg0KVGhlIHZlcnkgZmlyc3QgY2hhbmdlIEkgbGlrZSB0byBtYWtlIGlzIHRvIGJsb2NrIHRoZSBjb3JyZWxhdGlvbiBiZXR3ZWVuIHRoZSByYW5kb20gc2xvcGUgYW5kIGludGVyY2VwdC4gVGhpcyByZW1vdmVzIGEgc2luZ2xlIGZlYXR1cmUgZnJvbSBvdXIgcmFuZG9tIGVmZmVjdHMsIHNvIGl0IGlzIGEgZGVzaXJhYmxlIGZpcnN0IHN0ZXAuIFRvIGRvIHRoaXMsIEknbSBqdXN0IGdvaW5nIHRvIGFkZCBhbm90aGVyIGBgYHxgYGAgaW4gdGhlIHJhbmRvbSBlZmZlY3RzIHBvcnRpb24gb2YgdGhlIG1vZGVsLCBsaWtlIHRoaXMuDQoNCmBgYHtyfQ0Kbm9fY29yX3JhbmRvbSA8LSBsbWVyKEltcG9ydGFuY2UgfiAxDQogICAgICAgICArICgxK2R1bW15KGltcENhdCl8fFBJTiksIGRhdGEgPSBkYXRhMywgUkVNTD1GKQ0Kc3VtbWFyeShub19jb3JfcmFuZG9tKQ0KYGBgDQoNClRoYXQgd29ya2VkISBOb3RpY2UgaG93IHdlIGRpZG4ndCBnZXQgYW55bW9yZSBlcnJvcnM/IFRoaXMgcmFuZG9tIHN0cnVjdHVyZSBkb2VzIHNlZW0gdG8gZml0IG91ciBkYXRhIGEgYml0IGJldHRlci4gSSBhbHNvIHdhbnQgeW91IHRvIG5vdGljZSB0aGF0IHRoZSByZXNpZHVhbCB2YXJpYW5jZSBpbmNyZWFzZWQgZXZlciBzbyBzbGlnaHRseS4gVGhhdCdzIGJlY2F1c2Ugd2UgcmVtb3ZlZCBhIHJhbmRvbSBlZmZlY3QgdGhhdCB3YXMgYWNjb3VudGluZyBmb3Igc29tZSBvZiB0aGUgdmFyaWFuY2UgKHRoZSBjb3JyZWxhdGlvbiBiZXR3ZWVuIHRoZSByYW5kb20gc2xvcGUgYW5kIGludGVyY2VwdCkuIEl0J3MgaW1wb3J0YW50IHRvIGtlZXAgYSBjbG9zZSBleWUgb24geW91ciByZXNpZHVhbHMgYXMgeW91IGV4cGxvcmUgZGlmZmVyZW50IG1vZGVsIGZpdHMuDQoNCkRlcGVuZGluZyBvbiB0aGUgdHJhaW5pbmcgeW91J3ZlIHJlY2VpdmVkIGluIE1MTXMsIHNvbWUgd291bGQgc3RvcCBleGFtaW5pbmcgdGhlIHJhbmRvbSBzdHJ1Y3R1cmUgaGVyZS4gVGhlIGFyZ3VtZW50IGdvZXMgdGhhdCBldmVyeSByZWR1Y3Rpb24gaW4gdGhlIHJhbmRvbSBzdHJ1Y3R1cmUgaGFzIGEgcG90ZW50aWFsIChvciBpbmV2aXRhYmxlKSBpbmNyZWFzZSBpbiB0aGUgVHlwZSBJIGVycm9yIHJhdGUuIEhvd2V2ZXIsIEkgdXNlIHBhcnNpbW9uaW91cyBmaXR0aW5nIChCYXRlcywgS2xpZWdsLCBWYXNpc2h0aCwgJiBCYWF5ZW4sIDIwMTUpIHRvIHN5c3RlbWF0aWNhbGx5IHJlZHVjZSB0aGUgcmFuZG9tIHRlcm1zIGFuZCBmaW5kIHRoZSBzaW1wbGVzdCBtb2RlbCB0aGF0IGRvZXMgbm90IHNhY3JpZmljZSBtb2RlbCBmaXQuIFRvIGRvIHNvLCBJIHdpbGwgcmVtb3ZlIHJhbmRvbSBlZmZlY3RzIG9uZSBhdCBhIHRpbWUgYW5kIHNlZSB0aGUgcG90ZW50aWFsIGNoYW5nZSBpbiB0aGUgcmVzaWR1YWwgb2YgdGhlIG1vZGVsLiBUaGUgbW9tZW50IGEgbW9kZWwgZml0cyBzaWduaWZpY2FudGx5IHdvcnNlLCBhcyBkZXRlcm1pbmVkIGJ5IGEgQ2hpLXNxdWFyZSwgSSB3aWxsIHN0b3AgYW5kIGtlZXAgdGhlIG1vcmUgY29tcGxleCBtb2RlbC4gVGhpcyBwcm9jZXNzIGNhbiBiZSBsb25nLCBhbmQgaXQgaXMgaW5kZWVkIGxvbmcgZm9yIHRoZXNlIGRhdGEsIHNvIEkgd2lsbCBvbmx5IHNob3cgdGhlIGZpcnN0IHN0ZXAuDQoNCkluIHRoaXMgZmlyc3Qgc3RlcCwgSSBhbSBnb2luZyB0byByZW1vdmUgdGhlIHJhbmRvbSBpbnRlcmNlcHQuIFRvIGV4ZWN1dGUgdGhpcyBzdGVwLCBJIHNpbXBseSBuZWVkIHRvIGNoYW5nZSB0aGUgIjEiIGluIG15IHJhbmRvbSBlZmZlY3RzIHBvcnRpb24gdG8gIjAuIiBMZXQncyBzZWUgd2hhdCBoYXBwZW5zLg0KDQpgYGB7cn0NCm5vX2ludGVyY2VwdF9yYW5kb20gPC0gbG1lcihJbXBvcnRhbmNlIH4gMQ0KICAgICAgICAgKyAoMCtkdW1teShpbXBDYXQpfHxQSU4pLCBkYXRhID0gZGF0YTMsIFJFTUw9RikNCnN1bW1hcnkobm9faW50ZXJjZXB0X3JhbmRvbSkNCmBgYA0KDQpOb3RpY2UgdGhhdCB0aGUgcmVzaWR1YWwgdmFyaWFuY2UgaW5jcmVhc2VkIGJ5IGEgbG90PyEgVGhhdCBwcm9iYWJseSBtZWFucyB0aGlzIG1vZGVsIGlzIG5vdCBhcyBnb29kIGEgZml0LiBMZXQncyBmb3JtYWxseSB0ZXN0IG91ciBpbnR1aXRpb24uDQoNCmBgYHtyfQ0KYW5vdmEobm9fY29yX3JhbmRvbSwgbm9faW50ZXJjZXB0X3JhbmRvbSkNCmBgYA0KDQpBcyBleHBlY3RlZCwgdGhlIG5vIGludGVyY2VwdHMgbW9kZWwgZml0cyBzaWduaWZpY2FudGx5IHdvcnNlLiBOb3JtYWxseSwgdGhhdCB3b3VsZCBtZWFuIHRoYXQgSSB3b3VsZCBrZWVwIHRoZSBtb3JlIGNvbXBsZXggbW9kZWwuIEhvd2V2ZXIsIHdoZW4gSSBhZGRlZCBpbiB0aGUgbWFpbiBlZmZlY3RzLCB0aG9zZSBtb2RlbHMgZmFpbGVkIHRvIGNvbnZlcmdlIHdpdGggdGhlIG1vcmUgY29tcGxleCByYW5kb20gc3RydWN0dXJlcy4gQWZ0ZXIgaG91cnMgb2YgcG91cmluZyB0aHJvdWdoIG1hbnkgbWFueSBtb2RlbHMsIGl0IHR1cm5lZCBvdXQgdGhhdCB0aGUgc2ltcGxlc3QgbW9kZWwgd2FzIHRoZSBvbmx5IG9uZSB0aGF0IGNvbnZlcmdlZCBhY3Jvc3MgYWxsIGFuYWx5c2VzLiBCZWNhdXNlIHlvdSAqbXVzdCogaGF2ZSB0aGUgc2FtZSByYW5kb20gc3RydWN0dXJlIHRvIGNvbXBhcmUgYmV0d2VlbiBtb2RlbHMsIHRoYXQgaXMgdGhlIHN0cnVjdHVyZSBJIHdpbGwgdXNlIGhlcmUuIFRoZSBmaW5hbCByYW5kb20gc3RydWN0dXJlLCB0aGVuLCBvbmx5IGluY2x1ZGVzIGEgcmFuZG9tIGludGVyY2VwdC4NCg0KTm93IHRoYXQgd2UndmUgZXhhbWluZWQgb3VyIHJhbmRvbSBzdHJ1Y3R1cmUsIGxldCdzIHN0YXJ0IGFjdHVhbGx5IHRlc3Rpbmcgb3VyIGh5cG90aGVzZXMuDQo8YnIvPjxici8+PGJyLz4NCg0KDQoNCiMjIEZpeGVkIGVmZmVjdHMNCkluIE1MTXMsIGZpeGVkIGVmZmVjdHMgcmVmZXIgdG8gdGhlIGVmZmVjdHMgb2YgaW50ZXJlc3QuIEluIG90aGVyIHdvcmRzLCBvdXIgZml4ZWQgZWZmZWN0cyBhcmUgdGhlIHJlbGF0aW9uc2hpcHMgYmV0d2VlbiBvdXIgcHJlZGljdG9yIHZhcmlhYmxlcyBhbmQgb3VyIGNyaXRlcmlvbiB2YXJpYWJsZS4gSW4gdGhlIGNhc2Ugb2YgdGhpcyBzdHVkeSwgb3VyIGZpeGVkIGVmZmVjdHMgYXJlICoqZ29hbCBpbXBvcnRhbmNlKiosICoqcmVsZXZhbmNlIHRvIHN0cmVuZ3RoKiosICoqcmVsZXZhbmNlIHRvIHdlYWtuZXNzKiosIGFuZCB0aGUgdHdvLXdheSBpbnRlcmFjdGlvbnMgYmV0d2VlbiAqKmdvYWwgaW1wb3J0YW5jZSoqIGFuZCB0aGUgdHdvICoqcmVsZXZhbmNlKiogdmFyaWFibGVzLiBXZSB3aWxsIG5lZWQgZm91ciBkaWZmZXJlbnQgbW9kZWxzIHRvIGV4YW1pbmUgYWxsIG9mIG91ciBoeXBvdGhlc2VzLCBzdGFydGluZyB3aXRoIGEgbW9kZWwgdGhhdCBvbmx5IGluY2x1ZGVzIHRoZSBtYWluIGVmZmVjdHMgb2Ygb3VyIHByZWRpY3RvciB2YXJpYWJsZXMuDQoNCmBgYHtyfQ0KbWFpbl9lZmZlY3RzIDwtIGxtZXIodHJ1c3RSZWx5IH4gV2Vha1JlbEMgKyBTdHJSZWxDICsgaW1wQ2F0DQogICAgICAgICAgICAgICAgICAgICAgICAgKyAoMXxQSU4pLCBkYXRhID0gZGF0YTMsIFJFTUw9RikNCnN1bW1hcnkobWFpbl9lZmZlY3RzKQ0KYGBgDQoNCldoYXQgZG8gd2Ugbm90aWNlPyBGaXJzdCwgb3VyIHJlbGV2YW5jZSB0byBzdHJlbmd0aCBtZWFzdXJlIHN0cm9uZ2x5IGFuZCBzaWduaWZpY2FudGx5IHByZWRpY3RzIGdvYWwtc3BlY2lmaWMgdHJ1c3QuIFRoaXMgd2FzIHRoZSBlZmZlY3Qgd2Ugbm90aWNlZCBpbiBvdXIgZ3JhcGhzIGFib3ZlIGFuZCBjb25maXJtcyBib3RoIG91ciBoeXBvdGhlc2lzIGFuZCBpbnR1aXRpb25zIGZyb20gdGhlIGdyYXBoLiBTZWNvbmQsIGFuZCBpbiBsaW5lIHdpdGggdGhlIGdyYXBocyBidXQgYWdhaW5zdCBvdXIgaHlwb3RoZXNpcywgZ29hbCBpbXBvcnRhbmNlIGlzIGEgc2lnbmlmaWNhbnQgYW5kICpwb3NpdGl2ZSogcHJlZGljdG9yIG9mIHRydXN0LCBhbmQgdGhlIHJlbGV2YW5jZSB0byB3ZWFrbmVzcyBpcyBhIG1hcmdpbmFsbHkgKHVnaCwgSSBoYXRlIHRoYXQgd29yZCB0b28pIHNpZ25pZmljYW50IGFuZCAqcG9zaXRpdmUqIHByZWRpY3RvciBvZiB0cnVzdC4gSSdtIG5vdCBnb2luZyB0byBnbyB0aHJvdWdoIHRoZSBpbXBsaWNhdGlvbnMgZm9yIHRoZSB0aGVvcnkgaGVyZSwgc28gSSBlbmNvdXJhZ2UgeW91IHRvIHJlYWQgbXkgZGlzc2VydGF0aW9uLCBpZiB5b3UncmUgaW50ZXJlc3RlZC4gOikNCg0KTmV4dCwgbGV0J3MgYWRkIGVhY2ggb2YgdGhlIGludGVyYWN0aW9ucyBpbiBvbmUtYXQtYS10aW1lLiBXZSB3aWxsIHRlc3Qgd2hldGhlciB0aGUgbW9yZSBjb21wbGV4IG1vZGVsIGZpdHMgdGhlIGRhdGEgYmV0dGVyIHRoYW4gdGhlIHNpbXBsZXIgbW9kZWwgYWZ0ZXIgZWFjaCBzdGVwDQoNCmBgYHtyfQ0KIyMgQWRkaW5nIGludGVyYWN0aW9uIGJldHdlZW4gU3RyZW5ndGggYW5kIEltcG9ydGFuY2UNCnN0cmVuZ3RoX2ltcG9ydGFuY2UgPC0gbG1lcih0cnVzdFJlbHkgfiBXZWFrUmVsQyArIFN0clJlbEMqaW1wQ2F0DQogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgKyAoMXxQSU4pLCBkYXRhPWRhdGEzLCBSRU1MPUYpDQpzdW1tYXJ5KHN0cmVuZ3RoX2ltcG9ydGFuY2UpDQojIFRoZSBpbnRlcmFjdGlvbiBpcyBuZWdhdGl2ZSBidXQgbm90IHNpZ25pZmljYW50DQphbm92YShtYWluX2VmZmVjdHMsIHN0cmVuZ3RoX2ltcG9ydGFuY2UpDQojIE5vdCBhIHNpZ25pZmljYW50IGltcHJvdmVtZW50IGluIG1vZGVsIGZpdA0KIyMgQWRkaW5nIGludGVyYWN0aW9uIGJldHdlZW4gV2Vha25lc3MgYW5kIEltcG9ydGFuY2UNCndlYWtuZXNzX2ltcG9ydGFuY2U8LWxtZXIodHJ1c3RSZWx5IH4gV2Vha1JlbEMqaW1wQ2F0ICsgU3RyUmVsQw0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICsgKDF8UElOKSwgZGF0YT1kYXRhMywgUkVNTD1GKQ0Kc3VtbWFyeSh3ZWFrbmVzc19pbXBvcnRhbmNlKQ0KIyBUaGUgaW50ZXJhY3Rpb24gaXMgbm90IHNpZ25pZmljYW50DQphbm92YShtYWluX2VmZmVjdHMsIHdlYWtuZXNzX2ltcG9ydGFuY2UpDQojIE5vdCBhIHNpZ25pZmljYW50IGltcHJvdmVtZW50IGluIG1vZGVsIGZpdA0KYGBgDQoNCkluIGNvbnRyYXN0IHRvIG91ciBoeXBvdGhlc2VzLCBuZWl0aGVyIGludGVyYWN0aW9uIGlzIHNpZ25pZmljYW50LiBIb3dldmVyLCB3ZSBoYXZlIG9uZSBmaW5hbCBtb2RlbCB0byB0ZXN0IGJlZm9yZSB3ZSBnbyBob21lLiBXZSBzdGlsbCBuZWVkIHRvIHRlc3QgdGhlIG1vZGVsIHdpdGggYm90aCBpbnRlcmFjdGlvbnMgaW5jbHVkZWQuDQoNCmBgYHtyfQ0KIyMgQWRkaW5nIGJvdGggaW50ZXJhY3Rpb25zIGZvciBjb21wbGV0ZW5lc3MNCmZ1bGxfbW9kZWwgPC0gbG1lcih0cnVzdFJlbHkgfiBXZWFrUmVsQyppbXBDYXQgKyBTdHJSZWxDKmltcENhdA0KICAgICAgICAgICAgICAgICAgICAgICArICgxfFBJTiksIGRhdGE9ZGF0YTMsIFJFTUw9RikNCnN1bW1hcnkoZnVsbF9tb2RlbCkNCiMgTmVpdGhlciBpbnRlcmFjdGlvbiBpcyBzaWduaWZpY2FudA0KYW5vdmEoc3RyZW5ndGhfaW1wb3J0YW5jZSwgZnVsbF9tb2RlbCkNCmFub3ZhKHdlYWtuZXNzX2ltcG9ydGFuY2UsIGZ1bGxfbW9kZWwpDQojIE5vdCBhIHNpZ25pZmljYW50IGltcHJvdmVtZW50IGluIG1vZGVsIGZpdCBvdmVyIGVpdGhlciBzaW5ndWxhciBpbnRlcmFjdGlvbiBtb2RlbHMNCmBgYA0KDQpUaGUgZnVsbCBtb2RlbCBpcyBub3QgYW4gaW1wcm92ZW1lbnQgb3ZlciBlaXRoZXIgc2luZ2xlIGludGVyYWN0aW9uIG1vZGVscy4NCjxici8+PGJyLz48YnIvPjxici8+DQoNCg0KDQoNCiMgSW1wbGljYXRpb25zDQpTbyB3aGF0IGRpZCB3ZSBsZWFybj8gDQoqKkZpcnN0LCB0cnVzdCB2YXJpZXMgd2l0aGluIGEgcmVsYXRpb25zaGlwLCBhbmQgdGhhdCB2YXJpYWJpbGl0eSBpcyBwcmVkaWN0YWJsZS4qKg0KDQpTZWNvbmQsIHRoZSBtYWluIGVmZmVjdHMgb25seSBtb2RlbCB3YXMgdGhlIGJlc3QgZml0IGZvciB0aGUgZGF0YS4gQ29uc2VxdWVudGx5LCBpbiBjb250cmFzdCB0byBvdXIgaHlwb3RoZXNlcywgbmVpdGhlciBvZiB0aGUgaW50ZXJhY3Rpb25zIGJldHdlZW4gKipyZWxldmFuY2UqKiBhbmQgKipnb2FsIGltcG9ydGFuY2UqKiBwcmVkaWN0IGdvYWwtc3BlY2lmaWMgdHJ1c3QuDQoNClRoaXJkLCAqKnJlbGV2YW5jZSB0byB3ZWFrbmVzcyoqIGRvZXMgbm90IHNpZ25pZmljYW50bHkgcHJlZGljdCB0cnVzdCwgYW5kICoqZ29hbCBpbXBvcnRhbmNlKiogcG9zaXRpdmVseSBwcmVkaWN0cyB0cnVzdCwgYm90aCBvZiB3aGljaCBhcmUgY291bnRlciB0byBleHBlY3RhdGlvbnMuIA0KDQpGb3VydGggYW5kIGZpbmFsbHksIGFuZCBpbiBsaW5lIHdpdGggcHJlZGljdGlvbnMsICoqcmVsZXZhbmNlIHRvIHN0cmVuZ3RoKiogc3Ryb25nbHkgYW5kIHBvc2l0aXZlbHkgcHJlZGljdHMgdHJ1c3QuIA0KPGJyLz48YnIvPjxici8+PGJyLz4NCg0KDQoNCg0KIyBDb25jbHVzaW9uDQpJIGhvcGUgeW91IGhhdmUgZW5qb3llZCBhbmQgbGVhcm5lZCBzb21ldGhpbmcgZnJvbSB0aGlzIG92ZXJ2aWV3IGFuZCB3YWxrdGhyb3VnaCBvZiBteSBkaXNzZXJ0YXRpb24gbG9naWMgYW5kIGFuYWx5c2VzISANClBsZWFzZSBmZWVsIGZyZWUgdG8gY29udGFjdCBtZSBpZiB5b3UncmUgaW50ZXJlc3RlZCBpbiB0cnVzdCwgdGhlIHN0YXRzIHByZXNlbnRlZCBoZXJlLCBvciBqdXN0IHRvIGhhdmUgYSBmcmllbmRseSBjaGF0ISEgSSBsb3ZlIG1lZXRpbmcgbmV3IHBlb3BsZSBhbmQgbmVyZGluZyBvdXQgb24gdGhlc2UgdG9waWNzLg==