Probability

Definition
Probability is a mathematical concept used to predict how likely an event is to occur by assigning a number to represent whether something is definitely going to happen, definitely not going to happen, or anywhere in between. Although there are a lot of complicated things we can do with probability, the equation is simply the ratio of outcomes of interest to total outcomes and ranges from 0 (definitely won’t happen) to 1 (definitely will happen).
Although most of the concepts of probability are fairly simple, they can be counterintuitive. Take for example the following question.
Forewarning: I will try to trick you.
Base Rate Fallacy Example
Let’s say you have just met with your doctor who has informed you that you have tested positive for a fatal disease. To make things worse, this test is accurate 95% of the time.
- What is the probability you will die from this disease?
This question makes use of the base rate fallacy, which occurs when someone misjudges the likelihood of an event because they don’t take into account other relevant information. In this case, the relevant information is how infrequently the disease occurs in the population. Let’s take a look at Table 1 Below:
| Table 1 | |||
|---|---|---|---|
| Actually Sick | Actually Healthy | Probability of Having the Disease | |
| Test Positive | 95 | 4,995 | 1.90% |
| Test Nagative | 5 | 94,905 | 0.01% |
The columns labeled “Actually Sick” and “Actually Healthy” represent the number of people out of 100,000 that either really do have this fake illness or do not, respectively. The rows marked “Test Positive” and “Test Negative” indicate the number of people out of that 100,000 whose test told them they had the disease or not, respectively. In other words, the columns tell us about reality and the rows tell us about the test.
As you can see, 5 people who actually have the disease got test results that told them they were healthy, and 4,995 people who are healthy were told that they actually have the disease. If you add those groups up, you will find that 5% of the total number of people who took the test received wrong results (\(\frac{5,000}{100,000}\)). The test makers were not being inaccurate when they told you that their test was correct 95% of the time, they just failed to mention that the overwhelming majority of wrong tests happen when somebody who is actually healthy receives a test result that tells them they will die. Therefore, if you received those test results, you only have about a 1.90% chance of actually having the disease.
In order to know the probability of whatever it is you are interested in, you have to know the total number of possible outcomes (\(\frac{Outcome-of-Interest}{Total-Number-of-Possible-Outcomes}\)). Sometimes figuring that out is easy. For example, the probability of rolling a 1 on a single role of a six-sided die is \(\frac{1}{6}\) because there are 6 total possible outcomes. In the above example, the total number was 100,000 people. When I go over error in a later post, I will show tricks that statisticians have learned to essentially guess the total number of outcomes based on only knowing the details about a sample.
Continuous Outcomes
What happens if the thing we’re trying to predict is not a discrete outcome, like whether somebody is sick or not, and instead is continuous, like how many hours a consultant might bill next week based off their billing for the last month? The general equation for probability remains the same here, but now we look at area instead of counts.
Look at the graph below. There are many names for this distribution, but the two most common are the Normal Distribution and the Gaussian Distribution. I will use both terms interchangeably.
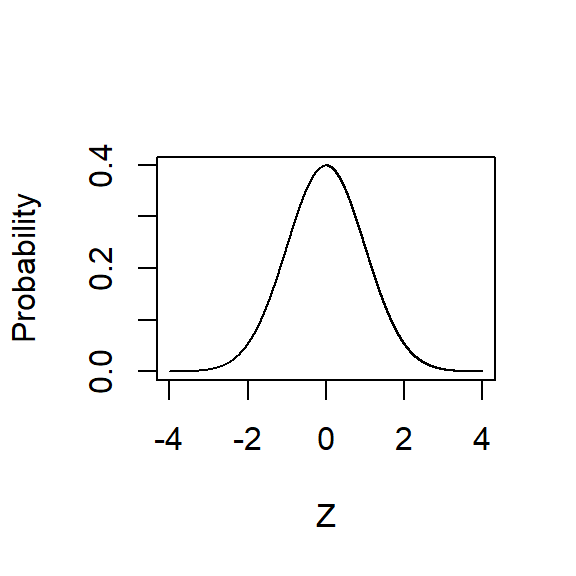
Normal Distribution
A lot of natural phenomena are normally distributed, like height and IQ. That’s pretty great because the normal distribution has a number of features that make things a bit easier when estimating probabilities and relationships, but those features are a bit out of the scope of this tutorial.
Because the normal distribution makes things a bit easier on estimating probabilities, statisticians, data scientists, and researchers often assume that an unknown distribution is normally distributed. Note: Good statisticians, data scientists, and researchers will always check those assumptions.
One of those benefits is that the normal distribution is precisely defined by an equation. As a consequence, you can define the probability of something by identifying the area of the normal distribution that corresponds to what you’re interested and divide that area by the total area. Ok, there’s a lot in this, so let’s step back and go over it slowly.
Let’s take a look at the normal distribution again, but this time I want you to notice the labels on the x- and y-axes.
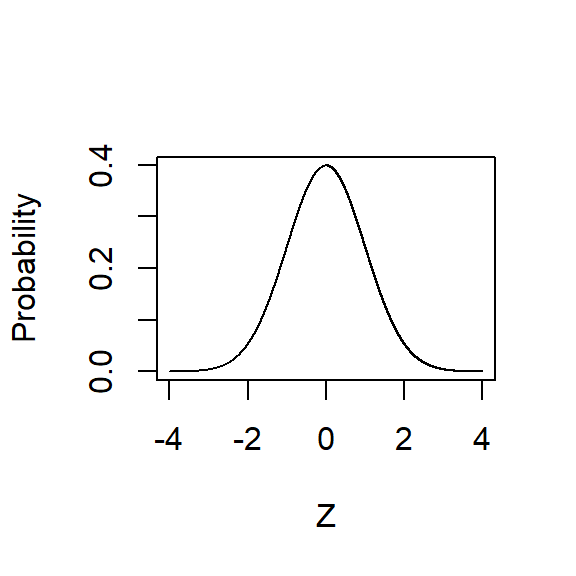
Z-scores
Along the Y-axis is plotted the proportion of the distribution that has that value. In other words, the taller that part of the curve, the more likely is that value. It’s clear, then, that if you have no other information about a distribution than its mean and that it’s normally distributed, your best guess is the mean of the distribution.
Along the X-axis, you’ll notice that it’s centered at 0 and goes from -4 to +4, and the axis is labeled “Z.” I’ve generated what’s called a “z-curve,” which is a way to standardize values from different distributions. It’s not necessary to fully understand what this means, but a quick example might help.
Imagine you want to see whether men are paid more than women in your organization for different types of employees (e.g., C-suite and customer-facing). Obviously, these two types of employees have very different salary expectations, so how would you compare the pay of C-suite with the pay of your cashiers? A “z-score” is a common way to place values from different distributions on a common scale.

Although the details are unnecessary for these purposes, it is important to know that there are specific probabilities associated with each z-score. For example, between the average of a distribution and +/-1 z-score is about 68% of the distribution. Between the average and +/- 2 z-scores is about 95% of the distribution.
Now, back to the question at hand. If we know that the area between +1 and -1 z-score is ~68% of the distribution, then we know that the area outside +1 and -1 z-score is ~32% of the population (100% – 68% = 32%). Because that area is on both sides of the curve, then there’s ~16% of the distribution that is greater than +1 z-score and ~16% of the distribution that is less than -1 z-score. That means we can convert the pay of all of our employees into z-scores and look at whether men are disproportionately represented in the top of the distribution across all positions (Spoiler: They probably are, and that’s a problem).
In fact, by converting your raw scores to z-scores, you can start to estimate the probability of randomly drawing a value that’s “greater than X,” or “between X and Z.” That is how you estimate probabilities when you are dealing with continuous values and not counts. And you thought you’d never have to think about area problems again!